Nghệ thuật cân bằng trong Redis: Tốc độ ánh sáng hay Sự an toàn tuyệt đối?
Trong thế giới của các hệ thống phân tán và kiến trúc phần mềm quy mô lớn, khi nhắc đến bộ nhớ đệm (caching) hay cơ sở dữ liệu tốc độ siêu cao, cái tên đầu tiên bật ra trong đầu các kỹ sư luôn là Redis. Không phải ngẫu nhiên mà hệ thống này lại trở thành một "ngôi sao" sáng giá 🌟, đứng sau và gánh vác hàng triệu request mỗi giây cho các nền tảng công nghệ hàng đầu thế giới.
Sự khác biệt biến Redis thành một thế lực không nằm ở những tính năng rườm rà, mà nằm ở một triết lý thiết kế tối giản nhưng đánh trúng "tử huyệt" về hiệu năng: "Ưu tiên bộ nhớ" (Memory-first).
Phần 1. Triết lý Redis: DNA của Tốc độ và Sự Linh hoạt
Các cơ sở dữ liệu truyền thống thường lấy ổ cứng (Disk) làm trung tâm để đảm bảo tính toàn vẹn dữ liệu lâu dài. Tuy nhiên, cái giá phải trả là Disk I/O – nút thắt cổ chai khét tiếng nhất trong kiến trúc máy tính. Redis đi theo một con đường hoàn toàn khác: mang toàn bộ "thế giới dữ liệu" đặt lên RAM.
Sự chênh lệch về độ trễ (latency) giữa RAM và ổ cứng (ngay cả với SSD NVMe) không phải là vài lần, mà là hàng nghìn cho đến hàng chục nghìn lần. Bằng cách loại bỏ hoàn toàn các tác vụ đọc/ghi đĩa cơ học chậm chạp ra khỏi luồng xử lý chính, Redis giải phóng sức mạnh tính toán và đạt được độ trễ ở mức Sub-millisecond (dưới một phần nghìn giây).
1.1 Tốc độ ánh sáng không chỉ đến từ RAM ⚡
Nói Redis nhanh chỉ vì nó "nằm trên RAM" là một sự thiếu sót lớn. Tốc độ ánh sáng của Redis thực chất là một bản giao hưởng hoàn hảo của các thiết kế kỹ thuật hệ thống đỉnh cao:
-
Cấu trúc dữ liệu bản địa tối ưu (Optimized Native Data Structures): Redis không chỉ lưu trữ chuỗi (String) đơn thuần. Nó cung cấp các cấu trúc dữ liệu cực kỳ tinh xảo như
Hash,Set, hoặcSorted Set(được backing bởi Skip List), giúp các thao tác tìm kiếm, sắp xếp diễn ra ngay trong bộ nhớ với độ phức tạp thuật toán lý tưởng là hoặc . -
Mô hình Đơn luồng (Single-threaded Event Loop): Nghe có vẻ ngược đời trong kỷ nguyên Multi-core, nhưng việc Redis sử dụng một luồng thực thi duy nhất kết hợp với cơ chế I/O Multiplexing (như epoll hoặc kqueue) là một nước đi thiên tài. Thiết kế này giúp Redis hoàn toàn miễn nhiễm với các rào cản tốn kém tài nguyên CPU của hệ thống đa luồng: không Context Switching, không Race Condition, và không cần Lock contention (tranh chấp khóa).
Chính vì triết lý này, Redis vượt xa khái niệm của một kho lưu trữ Key-Value thông thường, trở thành một "bộ khung xương" vững chắc cho các bài toán Real-time Analytics, Message Broker, hay Session Management.
1.2 "Dictionary Server": Sức mạnh từ sự đơn giản
Cái tên Redis (Remote Dictionary Server) phản ánh cách nó tổ chức dữ liệu: một cuốn từ điển khổng lồ nằm ở xa (Remote). Nơi mà dữ liệu được tổ chức theo cặp Key-Value.
- Phức tạp tính toán O(1): Trong một "Dictionary" (hay Hash Table), nếu bạn có chìa khóa (Key), bạn có thể tìm thấy giá trị (Value) ngay lập tức mà không cần phải quét qua toàn bộ dữ liệu. Đây là nền tảng giúp Redis giữ được hiệu suất ổn định bất kể tập dữ liệu lớn đến mức nào.
- RESP (Redis Serialization Protocol): Redis sử dụng một giao thức truyền tải cực kỳ tinh gọn, giúp việc đóng gói và giải nén yêu cầu giữa Client và Server diễn ra với chi phí thấp nhất có thể.
1.3. Vị thế: Kẻ đa tài "3 trong 1" 🎭
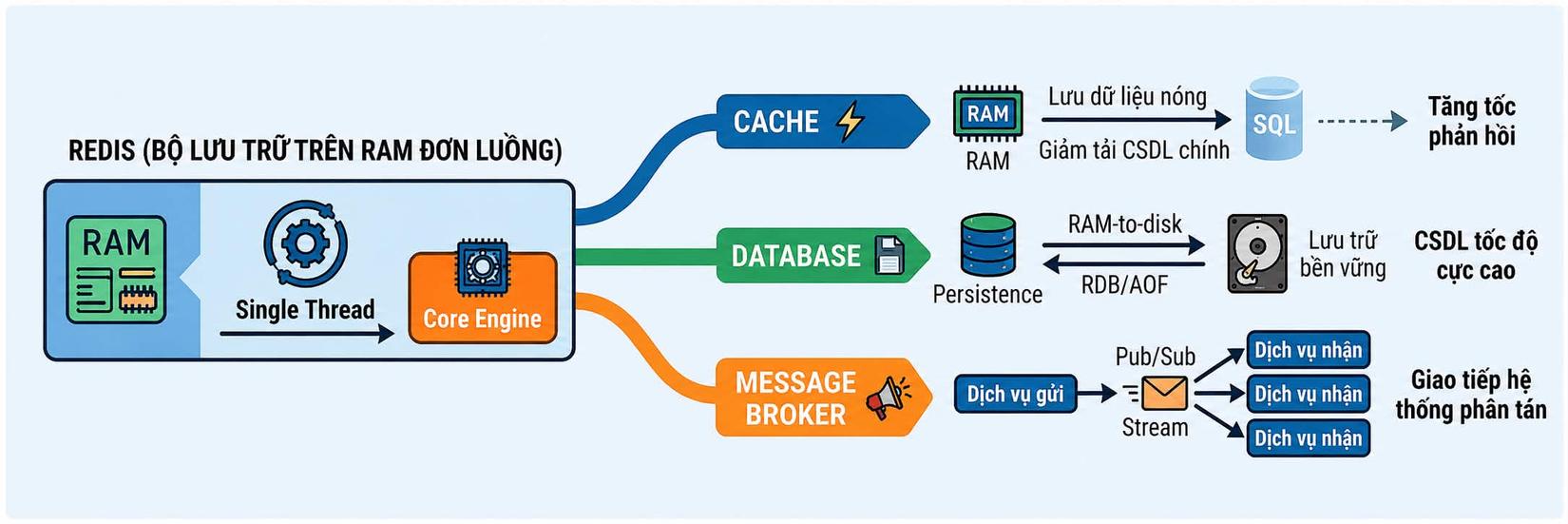
Redis không chịu ngồi yên trong một chiếc hộp định danh duy nhất. Nó đóng đồng thời 3 vai trò:
-
Cache ⚡: Đóng vai trò là "tiền đồn" cho CSDL chính, giúp giảm tải và tăng tốc phản hồi cho những dữ liệu được truy cập thường xuyên.
-
Database 💾: Với các cơ chế Persistence (RDB/AOF) mà chúng ta sẽ tìm hiểu ở phần sau, Redis hoàn toàn có thể đóng vai trò là CSDL chính cho các ứng dụng cần tốc độ cực cao và chấp nhận một biên độ rủi ro nhỏ về dữ liệu.
-
Message Broker 📣: Thông qua cơ chế Pub/Sub hoặc Stream, Redis trở thành hệ thống bưu điện, giúp các thành phần khác nhau trong hệ thống phân tán giao tiếp với nhau một cách mượt mà.
Tầng Nhân xử lý (Core Engine): Trái tim đơn luồng ⚙️
Mổ xẻ cơ chế đơn luồng (Single-threaded): Tại sao một luồng lại nhanh hơn nhiều luồng? ⚛️
Phần 2. Tầng Nhân xử lý (Core Engine): Trái tim đơn luồng ⚙️
Khi nhắc đến việc xây dựng các hệ thống backend chịu tải cao, "lẽ thường" của chúng ta là tối ưu hóa bằng kiến trúc xử lý đa luồng (multi-threading). Nhưng Redis lại đi ngược lại tư duy đó với một Core Engine hoàn toàn đơn luồng ở khâu xử lý lệnh, nhưng vẫn đạt mức hiệu năng khổng lồ (hàng trăm nghìn ops/sec).
Để mổ xẻ tận gốc sự nghịch lý này, chúng ta cần đi sâu vào kiến trúc phần cứng, cách quản lý bộ nhớ và mô hình xử lý I/O của Redis.
2.1. Mổ xẻ nghịch lý: Tại sao Một Luồng lại nhanh hơn Nhiều Luồng? ⚛️
Trong các hệ thống phân tán hay ứng dụng backend truyền thống, đa luồng giúp tận dụng CPU đa nhân. Nhưng đối với Redis, việc thêm luồng xử lý lệnh không những không làm nó nhanh hơn mà còn có thể kéo lùi hiệu năng. Dưới đây là 3 lý do cốt lõi:
A. Tắt nghẽn không nằm ở CPU (CPU is not the Bottleneck)
- Redis là một In-Memory Database. Mọi thao tác đọc/ghi đều diễn ra trực tiếp trên RAM. Tốc độ truy xuất RAM đo bằng nanosecond (ns). Với một core CPU hiện đại, việc xử lý một thao tác in-memory như GET hoặc SET mất chưa tới 1 microsecond. Do đó, "điểm nghẽn" (bottleneck) của Redis hiếm khi nằm ở năng lực tính toán của CPU, mà nằm ở Băng thông mạng (Network I/O) và Tốc độ bộ nhớ.
B. Loại bỏ hoàn toàn chi phí Chuyển đổi ngữ cảnh (Context Switching)
- Khi chạy đa luồng, hệ điều hành phải liên tục thực hiện Context Switching — lưu trạng thái của luồng hiện tại, tải trạng thái của luồng mới, làm "nhiễu" bộ nhớ đệm (CPU Cache miss). Các thao tác này tiêu tốn hàng ngàn chu kỳ CPU. Bằng cách giữ một luồng duy nhất cho việc thực thi (execution), Redis đảm bảo CPU Cache (đặc biệt là L1/L2) luôn đạt tỷ lệ hit cực cao, tối đa hóa hiệu năng xử lý tuần tự.
C. Triệt tiêu Lock Contention và Race Condition (Kiến trúc Lock-Free)
- Khi làm việc với các hệ thống đa luồng và dữ liệu dùng chung, việc sử dụng các cơ chế đồng bộ hóa (như synchronized, Mutex, hay Spinlocks) là bắt buộc để tránh Race Condition. Việc chờ đợi Lock (Lock contention) gây ra độ trễ cực lớn. Nhờ cơ chế đơn luồng, Redis không cần bất kỳ Lock nào khi thao tác trên các cấu trúc dữ liệu phức tạp của nó (như ZSet, Hash, List). Điều này cũng giúp mã nguồn của Redis gọn gàng và việc thiết kế các cấu trúc dữ liệu bên dưới trở nên tối ưu hơn rất nhiều.
2.2 Cơ chế I/O Multiplexing (Đa hợp I/O)🕹️
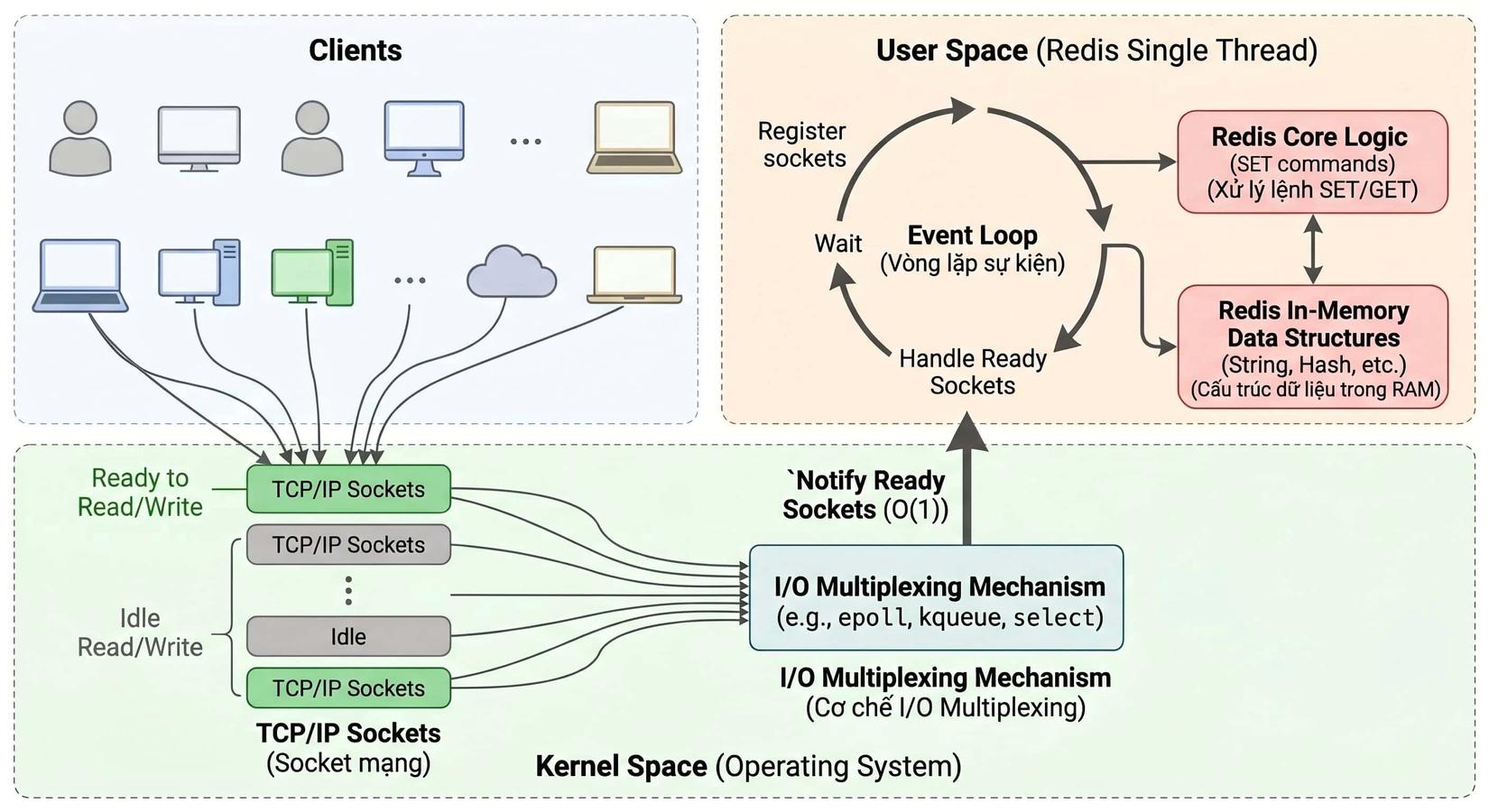
Thay vì tạo ra một luồng (thread) mới cho mỗi kết nối (như mô hình Thread-per-connection truyền thống), Redis sử dụng các system call của hệ điều hành như epoll (trên Linux), kqueue (macOS), hoặc select để giám sát hàng chục ngàn socket cùng lúc.
(epoll, kqueue, hay select chúng không phải là các câu lệnh gõ trên terminal, mà là các System Call (Lời gọi hệ thống). Đây là những API cấp thấp do chính Hệ điều hành (Linux, macOS, Unix) cung cấp để các phần mềm (như Redis, Nginx, Node.js) sử dụng để quản lý mạng. Chúng cho phép gom hàng vạn kết nối mạng lại và giao cho một luồng duy nhất quản lý. Thay vì phải tốn CPU đi hỏi thăm từng kết nối xem có dữ liệu không, hệ điều hành sẽ chủ động trả về danh sách chính xác các kết nối đang có dữ liệu, giúp tốc độ phản hồi gần như tức thì)
-
Non-blocking I/O: Redis cấu hình các socket (các phiên kết nối từ các Client/Ứng dụng đến Redis) ở chế độ non-blocking. Nếu không có dữ liệu để đọc, hàm read sẽ trả về ngay lập tức thay vì block luồng hiện tại.
-
Bộ chọn sự kiện (epoll): Redis giao việc "canh gác" các socket cho nhân hệ điều hành (Kernel). Khi một hoặc nhiều socket có dữ liệu sẵn sàng (sẵn sàng đọc, hoặc sẵn sàng ghi), Kernel sẽ "báo cáo" lại cho Redis.
2.3 Vòng đời trong Event Loop (Reactor Pattern)
Cơ chế đơn luồng của Redis hoạt động xoay quanh một vòng lặp sự kiện (Event Loop) liên tục:
-
Chờ sự kiện: Event Loop gọi epoll_wait để lấy danh sách các socket đang có sự kiện (ví dụ: có client vừa gửi lệnh GET).
-
Đưa vào hàng đợi (Event Queue): Các sự kiện được đẩy vào một hàng đợi.
-
Xử lý (Dispatcher/Event Handler): Luồng chính (Main Thread) lần lượt lấy từng sự kiện ra khỏi hàng đợi.
-
Nếu là Read Event: Đọc dữ liệu từ TCP buffer, parse thành lệnh Redis.
-
Command Execution: Thực thi lệnh (thao tác trực tiếp trên RAM). Vì chạy tuần tự, lệnh này không bao giờ bị gián đoạn bởi lệnh khác.
-
Nếu là Write Event: Ghi kết quả trả về vào socket buffer để gửi cho client.
-
Mô hình này giống như một siêu bồi bàn (Main Thread) phục vụ hàng ngàn bàn ăn. Thay vì đứng đợi ở từng bàn xem khách chọn món gì, bồi bàn này chỉ di chuyển đến những bàn đã nhấn "chuông gọi" (epoll), ghi nhận order, giao cho nhà bếp (Memory), rồi lập tức mang món ăn ra nếu đã sẵn sàng, không một giây phút nào bị lãng phí.
3. Sự tiến hóa: Khi "Đơn luồng" kết hợp với "Đa luồng" (Từ Redis 6.0+) 🚀
Mặc dù xử lý lệnh (Command Execution) đơn luồng là hoàn hảo, nhưng khi hệ thống scale lên mức cực lớn, các thao tác phân tích gói tin mạng (Network I/O read/write) bắt đầu chiếm quá nhiều thời gian của Main Thread.
Để giải quyết vấn đề này, từ bản Redis 6.0, kiến trúc I/O Threads (đa luồng cho I/O) đã được giới thiệu:
-
Network I/O (Multi-threaded): Quá trình đọc dữ liệu từ socket và parse cú pháp lệnh từ client, cũng như quá trình format kết quả trả về socket, giờ đây có thể được thực hiện song song bởi nhiều luồng (I/O Threads). Điều này giúp tận dụng các CPU đa nhân hiện đại.
-
Command Execution (Vẫn là Single-threaded): Lõi xử lý logic, cập nhật dữ liệu bộ nhớ VẪN LÀ ĐƠN LUỒNG. Các I/O Threads sau khi parse xong request sẽ đưa lệnh vào hàng đợi, và Main Thread vẫn sẽ lấy ra xử lý tuần tự.
Sự kết hợp này giúp Redis vừa giữ được tính nhất quán dữ liệu không-cần-lock (Lock-free) của kiến trúc đơn luồng, vừa phá vỡ được giới hạn về băng thông mạng nhờ xử lý I/O đa luồng.
Ngoài ra, Redis từ lâu cũng đã sử dụng các Background Threads (BIO) để xử lý các tác vụ nặng không ảnh hưởng trực tiếp đến data thao tác của client, như:
- Đóng file descriptors.
- Xóa các object lớn trong nền (lệnh
UNLINKthay vìDEL). - Đồng bộ AOF (Append Only File) xuống ổ cứng (
fsync).
Việc tách bạch rõ ràng giữa xử lý logic (nhanh gọn, in-memory) bằng một luồng và đẩy các tác vụ nghẽn cổ chai (Network, Disk I/O) sang các luồng phụ chính là chìa khóa tạo nên sức mạnh của Redis Core Engine.
Phần 3. Tầng Cấu trúc dữ liệu: Hộp công cụ đa năng 🗃️
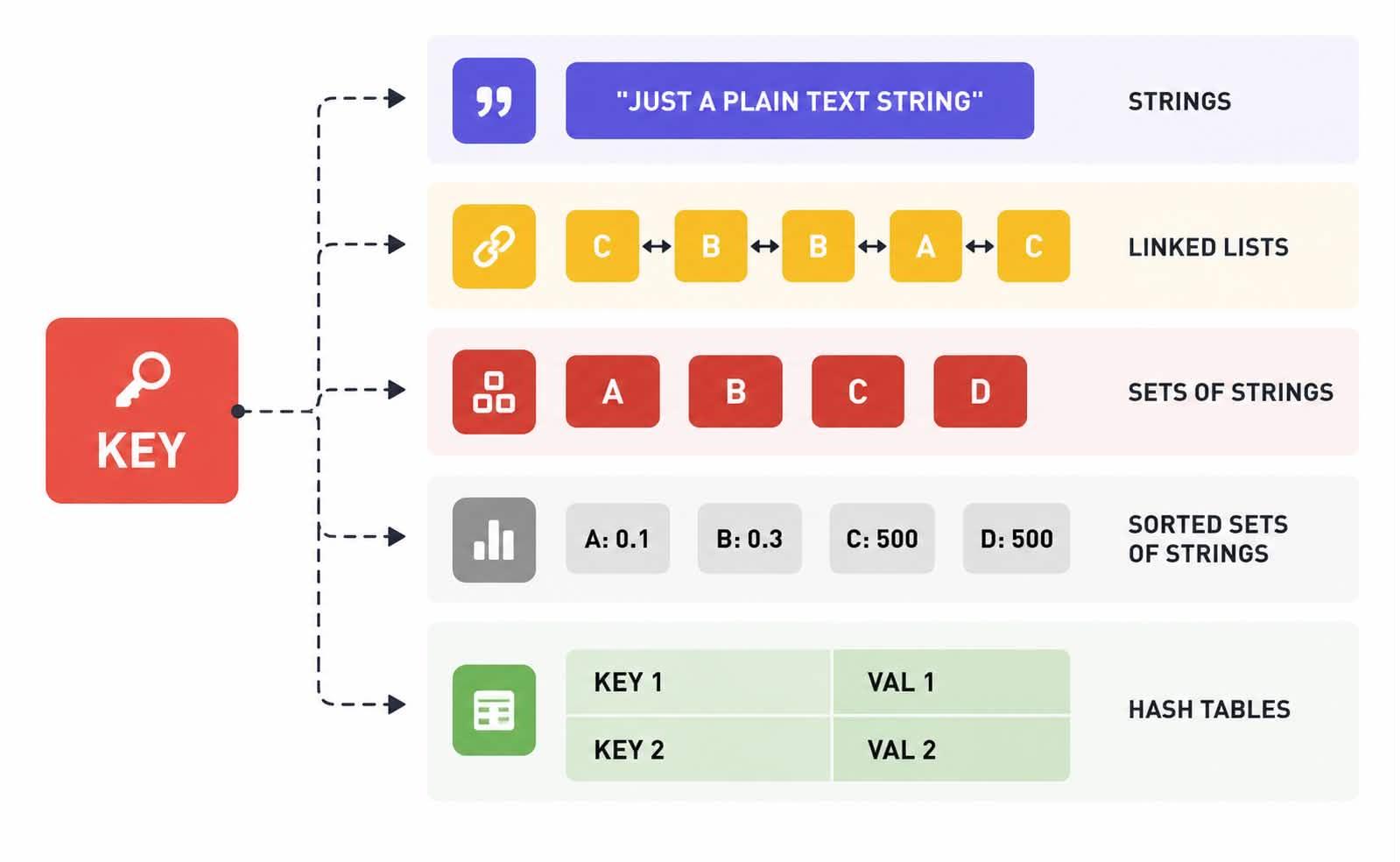
Nhiều người mới tiếp cận Redis thường nhầm tưởng nó chỉ là một bộ đệm (cache) lưu trữ các cặp Key-Value dưới dạng chuỗi (String) đơn giản. Thực tế, Redis tự định nghĩa mình là một "Data Structures Server" (Máy chủ Cấu trúc Dữ liệu).
Khả năng cung cấp các cấu trúc dữ liệu phong phú (Rich Data Types) và cách Redis "ép xung" bộ nhớ RAM cho từng loại dữ liệu chính là vũ khí giúp nó đứng vững trong các hệ thống xử lý hàng trăm triệu bản ghi với độ trễ tính bằng microsecond. Cũng chính vì thế, tốc độ của Redis không chỉ đến từ RAM, mà còn đến từ việc họ viết lại hoàn toàn các cấu trúc dữ liệu cơ bản để tối ưu đến từng byte. Chúng ta sẽ cùng xem xét các "mảnh ghép" tạo nên thực thể Redis.
Dưới đây là cách Redis thiết kế hộp công cụ này và những thủ thuật tối ưu hóa bộ nhớ ở tầng sâu nhất (under the hood).
3.1 Khám phá các loại "Hộp đựng" dữ liệu 📦
Redis cung cấp nhiều cấu trúc dữ liệu đa dạng. Mỗi loại đều được thiết kế để giải quyết các bài toán cụ thể với độ phức tạp thời gian tối ưu (thường là hoặc ).
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| Strings | Chuỗi nhị phân (Binary-safe), tối đa 512MB. | Cache HTML, lưu session, bộ đếm (Atomic Counters). |
| Hashes | Bản đồ giữa các trường (field) và giá trị (value). | Lưu thông tin User (ID, tên, email) - cực kỳ tiết kiệm RAM. |
| Lists | Danh sách các chuỗi sắp xếp theo thứ tự chèn. | Hàng đợi tin nhắn (Message Queue), danh sách bài đăng mới. |
| Sets | Tập hợp các phần tử không trùng lặp, không thứ tự. | lặp, không thứ tự. Lưu danh sách Tag, lọc người dùng trùng nhau, tập hợp bạn chung. |
| Sorted Sets | Giống Set nhưng mỗi phần tử đi kèm một điểm số (Score). | Bảng xếp hạng (Leaderboard), lập lịch nhiệm vụ (Task Scheduling). |
3.2 Nghệ thuật tối ưu hóa RAM: "Nhỏ nhưng có võ" 🧠
Bởi vì Redis là một In-Memory Database (sống hoàn toàn trên RAM – một tài nguyên cực kỳ đắt đỏ), mọi thiết kế cốt lõi của nó đều xoay quanh việc tối ưu hóa từng byte bộ nhớ. Để làm được điều này, Redis sử dụng những cấu trúc dữ liệu được "độ chế" riêng ở tầng thấp:
SDS (Simple Dynamic Strings): Đập bỏ sự tù túng của chuỗi C truyền thống
Redis được viết bằng C, nhưng chuỗi nguyên thủy trong C (C-strings) lại rất kém hiệu quả: tìm độ dài phải duyệt từ đầu đến cuối mất , không lưu được dữ liệu nhị phân (vì vướng ký tự kết thúc \0), và dễ gây tràn bộ đệm.
- Hiệu quả mang lại: Redis tự chế tạo ra SDS – một lớp bọc thông minh lưu sẵn metadata (độ dài chuỗi và dung lượng trống). Nhờ đó:
- Lấy độ dài chuỗi chớp nhoáng với .
- Hỗ trợ Binary-safe (lưu được mọi định dạng file nén, ảnh, audio).
- Sử dụng cơ chế cấp phát dư (Pre-allocation) và giải phóng lười (Lazy Freeing) để tránh việc phải xin hệ điều hành cấp phát lại RAM liên tục, giúp chống phân mảnh bộ nhớ hiệu quả.
Ziplist & Intset: Khối nén "xóa sổ" các con trỏ đắt đỏ
Các cấu trúc kinh điển như Linked List hay Hash Table cần dùng các con trỏ (pointers) để liên kết node. Trên hệ thống 64-bit, một con trỏ tốn tới 8 bytes. Nếu bạn chỉ muốn lưu một con số chiếm 1 byte mà phải cõng thêm hàng chục byte con trỏ thì đó là sự "lãng phí ngược" không thể chấp nhận.
- Hiệu quả mang lại: Khi một Hash, List hay Set có ít phần tử, Redis sẽ dồn tất cả vào một khối bộ nhớ liên tục (Ziplist hoặc Intset). Việc ép chặt dữ liệu nằm cạnh nhau và loại bỏ hoàn toàn các con trỏ dư thừa giúp tiết kiệm tới 60-80% RAM. Cấu trúc này cũng cực kỳ thân thiện với bộ nhớ đệm (CPU Cache Locality). (Lưu ý: Từ Redis 7.0 trở đi, Ziplist được thay thế dần bằng Listpack để giải quyết một số nhược điểm khi cập nhật, nhưng nguyên lý nén RAM vẫn giữ nguyên).
Encoding chuyển đổi tự động: Cỗ máy "sang số" thông minh
Không có cấu trúc dữ liệu nào là "viên đạn bạc". Ziplist tiết kiệm RAM xuất sắc nhưng khi mảng lên tới hàng ngàn phần tử, CPU sẽ bị vắt kiệt để duyệt tuần tự. Ngược lại, Hash Table tìm kiếm cực nhanh nhưng lại ngốn quá nhiều RAM.
-
Hiệu quả mang lại: Bạn không cần phải đau đầu lựa chọn, Redis có cơ chế tự động chuyển đổi siêu việt!
-
Khi dữ liệu nhỏ: Dùng cấu trúc nén để ưu tiên sinh tồn (tiết kiệm RAM).
-
Khi dữ liệu phình to vượt ngưỡng: Tự động bung ra thành cấu trúc phức tạp hơn (như Hash Table) để bảo vệ tốc độ xử lý (tối ưu CPU).
-
Tips cho DevOps: Bạn hoàn toàn có thể tự can thiệp vào "quyền sinh sát" này bằng cách tinh chỉnh các ngưỡng giới hạn (như
hash-max-ziplist-entries) trong fileredis.confđể hệ thống chạy theo đúng đặc thù dự án của mình.
-
3.3 Tại sao chọn đúng loại dữ liệu lại quan trọng? ⚖️
Nhiều người lầm tưởng Redis chỉ là một kho lưu trữ Key-Value đơn thuần (chỉ biết ném chuỗi JSON vào và đọc ra). Thực chất, định nghĩa chính xác của Redis là một Data Structure Server (Máy chủ cấu trúc dữ liệu). Việc chọn đúng loại dữ liệu ngay từ khâu thiết kế mang ý nghĩa sống còn đối với hiệu năng hệ thống bởi 3 lý do cốt lõi:
Tối ưu triệt để "Metadata Overhead" (Bài toán RAM)
RAM là tài nguyên đắt đỏ nhất của Redis. Mỗi top-level Key được tạo ra không chỉ chứa dữ liệu thực tế mà còn cõng theo một lượng lớn metadata (siêu dữ liệu quản lý, con trỏ, thông tin định tuyến).
Việc chọn cấu trúc dữ liệu tinh tế giúp bạn gom nhóm thông tin, từ đó kích hoạt các cơ chế nén ngầm (như Ziplist, Listpack hay Intset). Dùng 1 Hash để gom 10 thuộc tính của một User thay vì lưu thành 10 String riêng lẻ chính là cách ép Redis gỡ bỏ các metadata thừa thãi, tiết kiệm dung lượng đáng kinh ngạc.
Bảo vệ "Sinh mệnh" của Event Loop (Bài toán CPU & Thời gian)
Kiến trúc xử lý lệnh cốt lõi của Redis là đơn luồng (Single-threaded). Một truy vấn chậm sẽ chặn (block) toàn bộ hàng đợi, làm treo cả hệ thống. Chọn cấu trúc dữ liệu chính là bạn đang chọn độ phức tạp thuật toán cho các thao tác của mình.
- Ví dụ: Nếu bạn cần kiểm tra xem một ID đã tồn tại hay chưa. Nếu bạn lưu vào
List, Redis phải duyệt tuần tự mất – dữ liệu càng lớn, CPU càng thảm họa. Nhưng nếu bạn chọn đúng kiểuSet, thao tác tìm kiếm mất đúng , hệ thống sẽ phản hồi trong chớp mắt bất kể khối lượng dữ liệu.
"Offload" logic xử lý cho Application (Tận dụng sức mạnh nội tại)
Mỗi kiểu dữ liệu trong Redis được "đo ni đóng giày" cho một bài toán kinh điển. Nếu chọn đúng, bạn đẩy được các tác vụ tính toán nặng nề từ tầng Backend xuống thẳng tầng Database:
- Cần làm bảng xếp hạng thời gian thực? Đừng lưu mảng rồi kéo về Backend tự sort(). Hãy dùng Sorted Set (ZSET), Redis tự lo việc sắp xếp ngay lúc ghi liệu.
- Cần đếm số lượt truy cập độc lập (Unique Visitors) của hàng triệu người? Thay vì dùng Set gây tràn RAM, một cấu trúc đặc thù như HyperLogLog có thể đếm chính xác hàng triệu user chỉ với tối đa 12KB bộ nhớ.
Chọn kiểu dữ liệu trong Redis không phải là câu chuyện "lưu sao cho vừa", mà là bài toán thiết kế kiến trúc: Làm sao để vắt kiệt RAM hiệu quả nhất, đảm bảo mọi truy vấn tiệm cận , và tận dụng được các thuật toán đã được viết siêu tối ưu ở tầng lõi C của Redis.
3.4 💡 Các ví dụ thực tế: Chọn "Đúng" và "Sai" cấu trúc dữ liệu
Để thấy rõ sự khác biệt, hãy nhìn vào cách xử lý các bài toán hệ thống thông dụng:
Kịch bản 1: Xây dựng Bảng xếp hạng (Leaderboard)
-
❌ Lựa chọn sai (List hoặc String chứa JSON): Hệ thống lưu danh sách điểm số, sau đó Backend (như Java/Spring Boot) phải gọi lệnh để kéo toàn bộ mảng dữ liệu về RAM của ứng dụng, dùng hàm sort() tính toán rồi mới trả về. Vừa ngốn băng thông mạng, vừa lãng phí CPU của Backend.
-
✅ Lựa chọn đúng (Sorted Set - ZSET): Redis sinh ra ZSET cho việc này. Nhờ cấu trúc dữ liệu ngầm Skip List, Redis duy trì bảng xếp hạng thời gian thực. Việc cập nhật điểm hay lấy Top 10 người dùng cao nhất chỉ tốn chi phí thời gian . Backend chỉ cần gọi lệnh ZREVRANGE, dữ liệu trả về đã được sắp xếp chuẩn xác.
Kịch bản 2: Đếm số lượng User truy cập duy nhất trong ngày (Unique Visitors / UV)
-
❌ Lựa chọn sai (
Set): Bạn dùng Set lưu hàng triệu User ID để đếm bằng lệnh SCARD nhằm đảm bảo không bị trùng lặp. Với hệ thống lớn có 10 triệu active users, một Set có thể ngốn hàng chục MB RAM chỉ cho một ngày. Nếu lưu log trong 30 ngày, RAM sẽ phình to khủng khiếp. -
✅ Lựa chọn đúng (
HyperLogLog): Đây là cấu trúc dữ liệu sinh ra để đếm số lượng phần tử độc nhất với quy mô khổng lồ. Chấp nhận một tỷ lệ sai số toán học cực nhỏ (dưới 1%),HyperLogLogcó thể đếm chính xác hàng tỷ User mà dung lượng luôn cố định tối đa ở mức 12KB. Một sự cứu rỗi thực sự cho RAM!
Kịch bản 3: Quản lý Session của User / Cập nhật trạng thái từng phần
-
❌ Lựa chọn sai (
String): Lưu toàn bộ cục Session to đùng dưới dạng chuỗi JSON vào 1 Key String. Mỗi lần User cập nhật một thông tin rất nhỏ (ví dụ:last_active_time), Backend phải kéo nguyên chuỗi JSON về, parse ra, sửa thuộc tính đó, đóng gói lại thành JSON rồi ghi đè (SET) lên Redis. Chi phí serialize/deserialize và network round-trip là cực lớn. -
✅ Lựa chọn đúng (
Hash): Lưu Session vàoHash, mỗi thông tin là một field. Khi cần cập nhật thời gian hoạt động, Backend chỉ cần bắn một lệnh duy nhất:HSETsession:1001 last_active_time "10:00 AM". Cực kỳ nhẹ, tốc độ và không tiêu tốn băng thông thừa.
Phần 4. Tầng Lưu trữ bền vững (Persistence): Tấm khiên bảo vệ 💾
Redis là một cơ sở dữ liệu In-Memory (lưu trữ trên RAM), mang lại tốc độ cực nhanh, nhưng RAM lại có điểm yếu chí mạng: Tính dễ bay hơi (Volatile). Khi "tòa nhà" mất điện hoặc server gặp sự cố crash, toàn bộ dữ liệu trên RAM sẽ tan thành mây khói.
Để giải quyết vấn đề này, Redis trang bị một "tấm khiên bảo vệ" đa lớp gọi là tầng Persistence (Lưu trữ bền vững), giúp ghi dữ liệu từ RAM xuống ổ cứng (Disk) một cách khéo léo để có thể khôi phục lại khi khởi động. Redis cung cấp hai cơ chế chính: RDB và AOF.
4.1. RDB (Redis Database Backup): Bức ảnh chụp lấy liền 📸
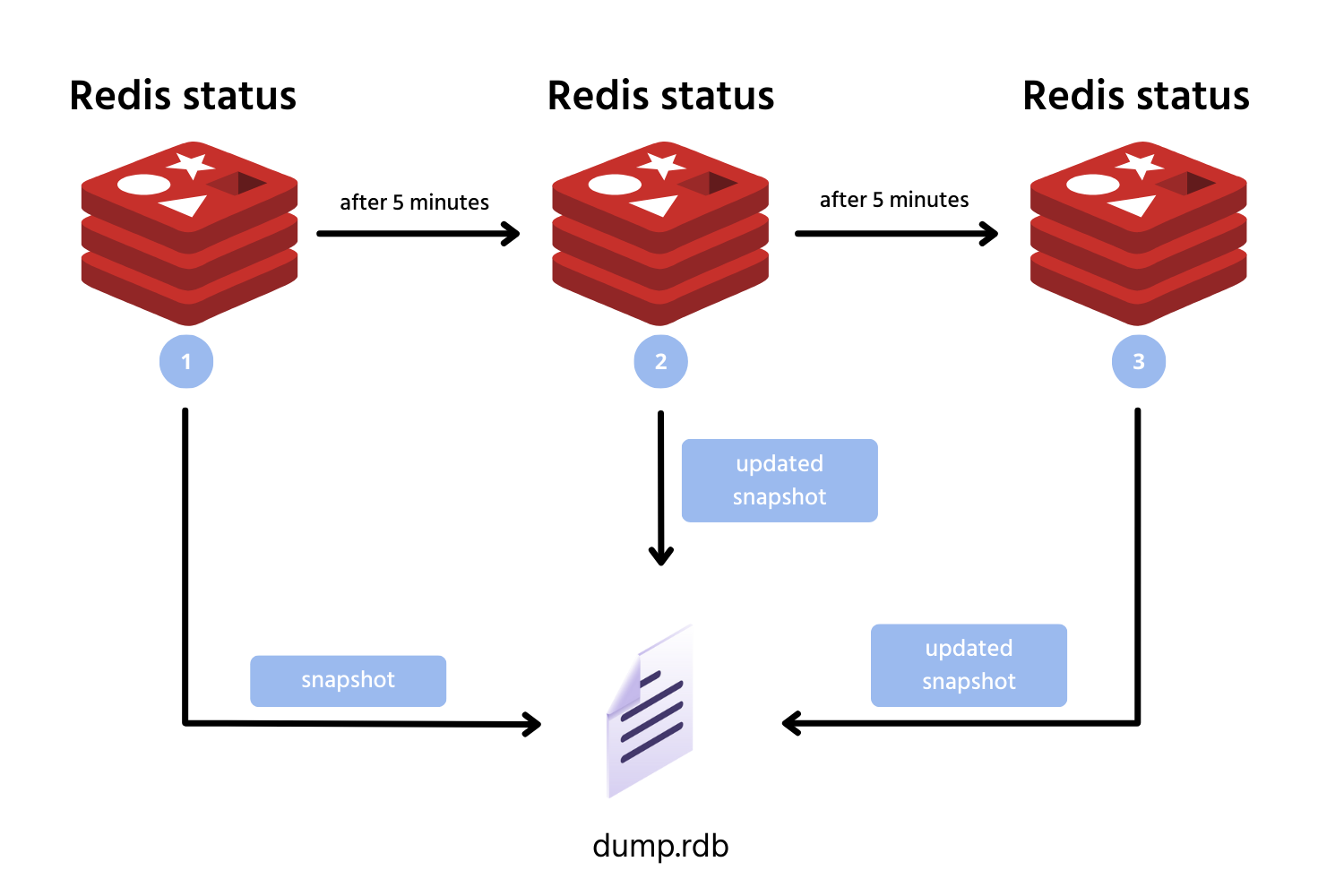
Cơ chế hoạt động:
RDB giống như việc bạn dùng máy ảnh chụp lại toàn bộ trạng thái dữ liệu trong RAM tại một thời điểm nhất định (Snapshot) và lưu thành một file nhị phân nén siêu nhỏ gọn (thường là dump.rdb). Bạn có thể cấu hình để Redis tự động "chụp" sau mỗi X phút nếu có Y key thay đổi (ví dụ: save 300 10 - lưu sau 300 giây nếu có ít nhất 10 thay đổi).
Cách RDB "chụp ảnh" mà không làm gián đoạn hệ thống:
Nếu Redis là đơn luồng, việc dừng lại để chép hàng chục GB dữ liệu ra ổ cứng sẽ làm "đứng" toàn bộ hệ thống. Để tránh điều này, Redis sử dụng kỹ thuật BGSAVE (Background Save) kết hợp với cơ chế Copy-on-Write (COW) của hệ điều hành:
-
Redis (Tiến trình cha) sẽ tạo ra một bản sao của chính nó (Tiến trình con - Forking).
-
Tiến trình con sẽ âm thầm đọc dữ liệu và ghi ra file RDB trên ổ cứng.
-
Trong lúc đó, Tiến trình cha vẫn tiếp tục phục vụ client. Nếu có client yêu cầu sửa đổi một dữ liệu đang được tiến trình con đọc, hệ điều hành sẽ "copy" vùng nhớ đó ra một chỗ khác để tiến trình cha sửa, giữ nguyên bản gốc cho tiến trình con tiếp tục ghi.
Ưu điểm: File nhỏ gọn, khởi động lại (phục hồi) cực kỳ nhanh. Rất tốt cho việc sao lưu định kỳ (backup).
Nhược điểm: Mất dữ liệu! Nếu bạn cài đặt chụp 5 phút/lần, và server sập ở phút thứ 4:59, bạn sẽ mất trắng toàn bộ dữ liệu của 5 phút vừa qua.
4.2. AOF (Append Only File): Cuốn nhật ký ghi chép tỉ mỉ 📝

Cơ chế hoạt động:
Khác với RDB chỉ lưu trạng thái cuối cùng, AOF hoạt động giống như một cuốn sổ nhật ký. Bất cứ khi nào có một lệnh làm thay đổi dữ liệu (như SET, HSET, DEL), Redis sẽ lập tức ghi lại chính "câu lệnh" đó vào cuối file AOF. Khi server khởi động lại, Redis chỉ cần "đọc lại nhật ký" và chạy lại các lệnh đó từ trên xuống dưới để khôi phục dữ liệu.
-
Ưu điểm: An toàn tuyệt đối. Mất mát dữ liệu được giảm xuống mức tối thiểu (có thể cấu hình).
-
Nhược điểm: File AOF sẽ phình to rất nhanh. Việc phục hồi dữ liệu cũng chậm hơn RDB vì phải chạy lại hàng triệu dòng lệnh. (Redis giải quyết việc file phình to bằng cơ chế AOF Rewrite - tự động gộp các lệnh dư thừa ở dưới nền).
4.3. Sự đánh đổi giữa Tốc độ và An toàn (Fsync Policies) ⚖️
Sự đánh đổi (trade-off) giữa Tốc độ (Speed) và Sự an toàn (Safety/Durability) là một trong những bài toán kiến trúc cốt lõi nhất của Redis. Redis bản chất là một cơ sở dữ liệu In-Memory (lưu trữ trên RAM), nên tốc độ của nó là vô song. Tuy nhiên, vì RAM là bộ nhớ khả biến (mất điện là mất dữ liệu), Redis buộc phải tương tác với ổ cứng (Disk I/O) hoặc mạng (Network I/O) để đảm bảo an toàn. Chính những tương tác này kéo lùi tốc độ của hệ thống. Dưới đây là 4 khía cạnh thể hiện rõ nhất sự đánh đổi này:
1. Cơ chế bền vững hóa dữ liệu (Persistence): RDB vs. AOF
Như đã giới thiệu ở phần 4.1 và 4.2, Redis cung cấp hai cơ chế ghi dữ liệu xuống ổ cứng, và mỗi cơ chế là một hình thái đánh đổi khác nhau:
-
RDB (Redis Database Backup - Snapshotting): Đánh đổi an toàn lấy tốc độ tối đa
- Dựa trên cách hoạt động của nó, chúng ta có thể thấy được rằng: RDB có một tốc độ đọc/ghi cực nhanh vì process chính không chạm vào ổ cứng. Tuy nhiên, bạn đang đánh đổi sự an toàn: Nếu server bị crash, bạn sẽ mất toàn bộ dữ liệu từ lần tạo snapshot cuối cùng (có thể là vài phút dữ liệu).
-
AOF (Append Only File): Đánh đổi tốc độ lấy sự an toàn
- Với AOF, vì phải liên tục ghi file, disk I/O sẽ tạo ra độ trễ (latency), làm giảm tốc độ xử lý tổng thể của Redis so với việc chỉ chạy trên RAM.
2. Chính sách fsync trong AOF: Nút vặn tối thượng
Trong cơ chế AOF, có một câu hỏi lớn: "Khi nào thì nên thực sự ghi dữ liệu xuống ổ đĩa vật lý?".
Ghi dữ liệu ra đĩa (Disk I/O) chậm hơn RAM hàng nghìn lần. Nếu Redis ghi trực tiếp ra đĩa với mỗi câu lệnh, nó sẽ đánh mất hoàn toàn sức mạnh "siêu tốc" của mình. Vì vậy, hệ điều hành thường lưu tạm dữ liệu vào một bộ đệm (OS Buffer), và Redis sử dụng lệnh fsync để ép hệ điều hành "xả" (flush) bộ đệm này xuống đĩa cứng vật lý.
Redis cho phép bạn chọn 1 trong 3 chiến lược appendfsync, và đây chính là nơi bạn phải đánh đổi:
-
appendfsync always(An toàn tuyệt đối - Tốc độ rùa bò): Mỗi khi có lệnh ghi, Redis lập tức gọi fsync để lưu thẳng xuống đĩa rồi mới báo thành công cho client. Tốc độ Redis lúc này sẽ bị giới hạn bởi tốc độ của ổ cứng. Rất ít ai dùng chế độ này trừ khi dữ liệu mang tính sống còn (như giao dịch tài chính cốt lõi). -
appendfsync everysec(Điểm cân bằng hoàn hảo - Khuyên dùng): Redis sẽ giao việc gọi fsync cho một luồng phụ (Background Thread) chạy định kỳ 1 giây 1 lần. Luồng chính vẫn xử lý lệnh trên RAM ở tốc độ tối đa. Sự đánh đổi: Nếu server bị rút điện đột ngột, bạn chỉ mất tối đa 1 giây dữ liệu. Đây là cấu hình mặc định và được dùng nhiều nhất. -
appendfsync no(Tốc độ tối đa - Mặc kệ số phận): Redis đẩy dữ liệu cho hệ điều hành và phó mặc việc ghi xuống đĩa cho OS tự quyết định (thường là 30 giây/lần trên Linux). Tốc độ cực nhanh, nhưng rủi ro mất dữ liệu rất cao nếu sập nguồn.
(Từ phiên bản Redis 4.0 trở đi, người ta thường dùng Hybrid Persistence: Kết hợp file RDB làm nền tảng và dùng AOF để ghi các thay đổi diễn ra kể từ lúc chụp RDB, mang lại sự kết hợp hoàn hảo giữa thời gian phục hồi nhanh và độ an toàn cao).
3. Replication (Đồng bộ Master - Replica)
Trong hệ thống phân tán, sự an toàn còn có nghĩa là dữ liệu phải tồn tại ở nhiều Node (phòng trường hợp Node chính bị cháy phần cứng).
-
Asynchronous Replication (Mặc định): Khi Client gửi lệnh ghi vào Master, Master ghi vào RAM, báo "Thành công" (OK) cho Client ngay lập tức, sau đó mới âm thầm đẩy dữ liệu sang Replica.
- Đánh đổi: Tốc độ phản hồi cho Client cực nhanh. Nhưng nếu Master trả về OK rồi đột ngột chết trước khi kịp đẩy dữ liệu sang Replica, lượng dữ liệu đó sẽ biến mất khi Replica được thăng cấp lên làm Master mới.
-
Synchronous Replication (Lệnh WAIT): Bạn có thể ép Redis chờ cho đến khi dữ liệu được ghi thành công ở một số lượng Replica nhất định rồi mới trả kết quả cho Client.
- Đánh đổi: An toàn tuyệt đối khỏi lỗi phần cứng đơn lẻ, nhưng Client phải chờ Network I/O giữa các Node, làm tăng độ trễ (latency) của request lên gấp nhiều lần.
4. Chi phí của quá trình Forking (Copy-on-Write)
Ngay cả khi dùng RDB hoặc tính năng AOF Rewrite (để thu gọn file log), Redis cũng phải gọi system call fork() để tạo background process.
-
Hệ điều hành sử dụng cơ chế Copy-on-Write (CoW). Tức là ban đầu, process cha (phục vụ client) và process con (ghi đĩa) dùng chung một vùng RAM.
-
Đánh đổi: Nếu trong lúc đang ghi đĩa (vốn dĩ rất chậm) mà hệ thống của bạn có quá nhiều lệnh Write mới đẩy vào, OS buộc phải copy các trang bộ nhớ (memory pages) ra các vùng RAM mới để không làm hỏng dữ liệu đang ghi. Quá trình copy này ngốn CPU và có thể gây ra hiện tượng Latency Spike (chậm đột biến), khiến các request bình thường bị nghẽn lại vài chục đến vài trăm phần nghìn giây. Ở các hệ thống quy mô lớn, đây là một sự đánh đổi cực kỳ đau đầu.
Tóm lại: Redis được sinh ra là để chạy nhanh. Bạn càng cố gắng cấu hình (bật
alwaysfsync, ép đồng bộ chờ Replica) để biến nó thành một Database an toàn và kiên cố như PostgreSQL hay MySQL, bạn càng đánh mất đi vũ khí mạnh nhất của nó là Độ trễ siêu thấp (Sub-millisecond Latency). Tùy vào loại dữ liệu (ví dụ: Session/Cache thì ưu tiên tốc độ, Balance/Billing thì ưu tiên an toàn) mà kỹ sư hệ thống sẽ chọn điểm rơi phù hợp.
4.4. Nghệ thuật Cân bằng: Giải pháp từ Kiến trúc và Vận hành"
Trong thế giới thực, chúng ta hiếm khi cấu hình hệ thống ở mức cực đoan (chỉ chọn 100% tốc độ hoặc 100% an toàn), mà sẽ tìm kiếm điểm rơi tối ưu.
Thay vì chấp nhận một sự đánh đổi cực đoan, các kỹ sư hệ thống có những chiến lược thông minh để đạt được "sự cân bằng" giữa tốc độ và độ bền vững.
1. Bức tranh lai (Hybrid Persistence): RDB-AOF Mixed Mode
Kể từ Redis 4.0, một tính năng tuyệt vời mang tên Mixed Persistence đã ra đời để dung hòa RDB và AOF.
-
Cách hoạt động: Khi file AOF phình to và cần được viết lại (AOF Rewrite), Redis sẽ không ghi lại từng dòng lệnh từ đầu nữa. Thay vào đó, nó ghi phần dữ liệu hiện tại dưới định dạng nhị phân siêu gọn nhẹ của RDB, và chỉ dùng định dạng text của AOF cho những lệnh write mới phát sinh trong lúc đang rewrite.
-
Điểm cân bằng: Khi khởi động lại server, Redis nạp lại phần base RDB cực nhanh (tốc độ của RDB), sau đó chạy lại một đoạn ngắn AOF ở đuôi để lấy lại dữ liệu mới nhất (sự an toàn của AOF).
2. Sự cân bằng ở Tầng Kiến trúc: Không ép Redis "làm việc sai sở trường"
Lỗi lớn nhất là coi Redis như một Database chính (Source of Truth) cho mọi loại dữ liệu. Sự cân bằng tốt nhất đến từ mô hình Cache-Aside Pattern.
-
Chiến lược: Giao nhiệm vụ "An toàn tuyệt đối" cho các RDBMS vật lý (MySQL/PostgreSQL). Giao nhiệm vụ "Tốc độ chớp nhoáng" cho Redis.
-
Vận hành: Mọi lệnh Write quan trọng đều ghi xuống DB thật. Redis chỉ lưu bản sao tạm thời để phục vụ Read. Nếu Redis sập và mất toàn bộ RAM, hệ thống chỉ bị chậm đi (do Cache Miss phải chọc xuống DB), nhưng dữ liệu không hề biến mất.
5.3. Phân loại dữ liệu (Data Categorization): Không "cào bằng" rủi ro
Bạn có thể chạy nhiều instance Redis hoặc thiết lập các chính sách khác nhau tùy vào bản chất dữ liệu:
-
Cụm Redis A (Ưu tiên tốc độ): Lưu trữ Session người dùng, View Count (số lượt xem), Rate Limiting. Cụm này có thể chỉ dùng RDB (snapshot 15 phút/lần) hoặc thậm chí tắt luôn Persistence chạy 100% In-memory. Mất vài session thì bắt user đăng nhập lại, không sao cả.
-
Cụm Redis B (Ưu tiên an toàn): Lưu trữ Giỏ hàng (Cart), Flash Sale Inventory (Tồn kho khuyến mãi). Cụm này bật AOF
everysechoặc kết hợp Mixed Persistence, đi kèm với cấu hình Master-Replica có độ tin cậy cao.
❓️Ở đây, mình có một câu hỏi để test độ hiểu sâu của các bạn: Trong mô hình Cache-Aside, nếu Redis sập và mất dữ liệu, lượng request khổng lồ sẽ đổ dồn thẳng xuống MySQL/PostgreSQL gây ra hiện tượng sập dây chuyền (Cache Stampede). Làm thế nào để cân bằng rủi ro này trong kiến trúc?
Phần 5: Tầng Kiến trúc hệ thống (Topologies): Khả năng mở rộng và Sẵn sàng cao 🏗️
Sau khi trang bị "tấm khiên" Persistence (RDB/AOF) để bảo vệ dữ liệu trên một máy chủ, câu hỏi tiếp theo đặt ra là: Điều gì xảy ra nếu toàn bộ máy chủ đó (về mặt vật lý) bị hỏng phần cứng, đứt cáp mạng, hoặc dung lượng RAM đã đạt giới hạn tối đa?
Đó là lúc chúng ta phải bước ra khỏi một cỗ máy đơn lẻ và tiến vào Tầng Kiến trúc hệ thống (Topologies). Redis cung cấp 3 mô hình triển khai từ cơ bản đến phức tạp để giải quyết các bài toán về tính sẵn sàng cao (High Availability) và khả năng mở rộng (Scalability).
1. Standalone & Replication: Nền móng cơ bản 🧱
Đây là mô hình đơn giản nhất, thường bao gồm một node Master (Chủ) và một hoặc nhiều node Replica / Slave (Tớ).
-
Cơ chế hoạt động: Bạn chỉ thực hiện thao tác GHI (Write) trên Master. Master sau đó sẽ đồng bộ dữ liệu (bất đồng bộ) xuống các Replicas. Các thao tác ĐỌC (Read) có thể được phân tải xuống Replicas để giảm áp lực cho Master.
-
Điểm yếu chí mạng (SPOF - Single Point of Failure): Nếu node Master "đột tử", bạn vẫn có thể đọc dữ liệu từ Replicas, nhưng toàn bộ hệ thống sẽ không thể ghi thêm dữ liệu mới. Quản trị viên (con người) phải can thiệp bằng tay: Chọn một Replica, cấu hình nó thành Master mới, và trỏ các ứng dụng backend về IP của Master mới này. Việc này gây ra "Downtime" (thời gian chết) hệ thống.
2. Sentinel (Lính canh): Sự sống còn tự động (High Availability) 💂♂️
Để giải quyết nhược điểm "phải can thiệp bằng tay" của mô hình Standalone, Redis giới thiệu Sentinel. Sentinel không lưu trữ dữ liệu, nó đóng vai trò là những "Lính canh" liên tục giám sát sức khỏe của các node Redis.
Cơ chế Failover (Chuyển đổi dự phòng) tự động:
-
Giám sát (Monitoring): Cần triển khai ít nhất 3 node Sentinel (để tránh hiện tượng split-brain/chia rẽ mạng). Các Sentinel này liên tục "ping" (hỏi thăm) Master và các Replicas.
-
Phát hiện lỗi: Nếu một Sentinel thấy Master không trả lời, nó sẽ đánh dấu là SDown (Subjectively Down - Lỗi theo góc nhìn cá nhân).
-
Bầu chọn (Quorum/Voting): Sentinel này sẽ hỏi các Sentinel khác. Nếu đa số (Quorum) đều xác nhận Master đã "chết", hệ thống chuyển sang trạng thái ODown (Objectively Down - Lỗi khách quan toàn cục).
-
Thăng cấp (Promotion): Các Sentinel sẽ tự động họp bàn, chọn ra Replica có dữ liệu cập nhật mới nhất và "thăng cấp" nó lên làm Master mới.
-
Cập nhật cấu hình: Sentinel báo cho các ứng dụng backend biết địa chỉ IP của Master mới để tiếp tục thao tác GHI mà không cần con người can thiệp.
-
Khi nào dùng? Khi bạn cần hệ thống luôn sống (High Availability) nhưng tổng lượng dữ liệu có thể nằm gọn trong RAM của một máy chủ (ví dụ: < 64GB).
3. Cluster (Cụm máy chủ): Chinh phục biển dữ liệu khổng lồ 🌐
Sentinel giải quyết được bài toán "sống sót", nhưng không giải quyết được bài toán "dung lượng". Nếu bạn có 500GB dữ liệu cache, việc nhét tất cả vào một máy chủ là bất khả thi hoặc quá đắt đỏ. Redis Cluster ra đời để chia nhỏ dữ liệu (Sharding) ra nhiều máy chủ khác nhau.
Cơ chế Phân mảnh (Sharding) bằng Hash Slots:
Cluster không sử dụng Master-Replica đơn thuần, mà là một mạng lưới Multi-Master (Nhiều Chủ).
-
Redis Cluster chia không gian lưu trữ thành chính xác 16,384 Hash Slots (Khe băm).
-
Giả sử bạn có 3 node Master (A, B, C):
-
Node A quản lý slot từ 0 đến 5460.
-
Node B quản lý slot từ 5461 đến 10922.
-
Node C quản lý slot từ 10923 đến 16383.
-
-
Khi bạn lưu một key (ví dụ: SET user:100 "Bach"), Redis sẽ chạy một thuật toán CRC16("user:100") mod 16384 để ra một con số (ví dụ: 6000). Vì 6000 nằm trong khoảng của Node B, dữ liệu này sẽ được lưu thẳng vào Node B.
Gossip Protocol: Các node trong Cluster liên tục "nói chuyện" với nhau (Gossip protocol) để chia sẻ trạng thái. Nếu bạn gửi lệnh lấy user:100 đến Node A, Node A biết rằng slot 6000 thuộc về Node B, nó sẽ trả về lỗi MOVED để chuyển hướng client sang Node B lấy dữ liệu.
-
Tính sẵn sàng cao: Mỗi node Master trong Cluster đều có ít nhất 1 node Replica đi kèm. Nếu Master B chết, Replica của nó sẽ tự động lên thay (Cluster tự tích hợp cơ chế failover mà không cần cài thêm Sentinel).
-
Sự đánh đổi: Tuy mạnh mẽ, nhưng Cluster làm hệ thống phức tạp hơn. Các thao tác multi-key (như giao dịch Transaction, hay lệnh thao tác nhiều key cùng lúc) sẽ không hoạt động nếu các key đó không rơi vào cùng một Hash Slot.
Phần 6: Kết nối từ Java (Client Libraries)
Trong hệ sinh thái ứng dụng enterprise, đặc biệt là khi xây dựng các backend system đòi hỏi xử lý đồng thời (concurrency) cao, việc chọn sai Redis client có thể bóp nghẹt toàn bộ ưu điểm "tốc độ ánh sáng" mà chúng ta vừa nhắc đến. Dữ liệu có thể nằm trên RAM, nhưng nếu luồng (thread) của ứng dụng phải chờ đợi nhau để lấy data, độ trễ sẽ dội ngược lại phía người dùng.
Cùng mổ xẻ "bộ ba quyền lực" trong thế giới Java để xem đâu là mảnh ghép phù hợp cho kiến trúc của bạn:
1. Jedis: Kẻ tiên phong và bài toán Connection Pool
Jedis là client lâu đời và có API gần gũi nhất với các câu lệnh Redis thuần (CLI). Nó tuân theo mô hình Synchronous/Blocking.
-
Bản chất: Gửi một command, block luồng hiện tại, chờ Redis phản hồi, rồi mới đi tiếp.
-
Tử huyệt Thread-safe: Một instance của Jedis không thể được chia sẻ giữa nhiều thread. Nếu hai thread cùng gọi một object Jedis, luồng I/O (Socket) sẽ bị rối loạn, dẫn đến sai lệch dữ liệu.
-
Cách giải quyết: Bắt buộc phải dùng JedisPool. Mỗi request sẽ mượn một connection từ pool, dùng xong trả lại.
-
Đánh đổi: Trong một hệ thống tải cao, việc duy trì một connection pool khổng lồ sẽ gây áp lực lớn lên tài nguyên hệ thống và làm tăng overhead của Garbage Collection.
2. Lettuce: Cú lột xác bất đồng bộ với Netty 🍃
Kể từ Spring Boot 2.0, Spring Data Redis đã chính thức "ly hôn" Jedis để chọn Lettuce làm client mặc định. Tại sao lại có sự ưu ái này?
-
Kiến trúc Event-Driven: Lettuce được xây dựng trên nền tảng Netty – framework mạng bất đồng bộ (asynchronous) khét tiếng của Java.
-
Thread-safe & Multiplexing: Khác với Jedis, bạn có thể (và nên) dùng một connection duy nhất của Lettuce cho hàng ngàn thread. Các lệnh (commands) từ nhiều luồng khác nhau sẽ được Netty gom lại (pipelining), gửi đi bất đồng bộ không chờ đợi (Non-blocking I/O), và khi có kết quả, event loop sẽ trigger callback trả về đúng luồng yêu cầu.
-
Hiệu năng: Khai thác tối đa hiệu suất CPU, giảm thiểu triệt để chi phí Context Switching và số lượng TCP connection phải mở. Đây là "vũ khí" chuẩn mực cho các hệ thống Reactive hoặc có throughput khổng lồ.
3. Redisson: Khi Redis vượt khỏi giới hạn Caching 🚀
Nếu Jedis và Lettuce tập trung vào việc "giao tiếp" với Redis sao cho nhanh nhất, thì Redisson lại tiếp cận theo một hướng hoàn toàn khác: Biến Redis thành một phần mở rộng của JVM.
-
Abstraction cấp cao: Bạn không thao tác với "String" hay "Hash" của Redis nữa, mà làm việc trực tiếp với các interfaces quen thuộc của java.util.concurrent như ConcurrentMap, Queue, Semaphore, CountDownLatch. Redisson tự động map chúng xuống Redis một cách trong suốt.
-
Distributed Lock (Khóa phân tán): Đây là "đặc sản" làm nên tên tuổi của Redisson. Khi xử lý các luồng nghiệp vụ phức tạp (ví dụ: trừ tiền tài khoản, claim bảo hiểm) trên một hệ thống microservices có hàng chục instances cùng chạy, bạn không thể dùng synchronized của Java. Redisson cung cấp RLock (hỗ trợ cả thuật toán Redlock), giúp kiểm soát đồng bộ hóa dữ liệu phân tán một cách an toàn, chống Deadlock cực kỳ hiệu quả bằng cơ chế Watchdog.
| Tiêu chí | Jedis | Lettuce | Redisson |
|---|---|---|---|
| Mô hình | Đồng bộ (Blocking) | Bất đồng bộ (Non-blocking), Reactive | Bất đồng bộ, Hướng đối tượng phân tán |
| Thread-safe | ❌ Không (Cần Connection Pool) | ✅ Có (Chia sẻ 1 connection tốt) | ✅ Có |
| Trường hợp sử dụng | Các dự án cũ, script đơn giản, batch job chạy tuần tự. | Bất đồng bộ (Non-blocking), Reactive | Cần đồng bộ hóa phân tán (Distributed Locks, Semaphores), xử lý logic phức tạp. |
💡Tip trong thực tế: Rất nhiều hệ thống enterprise quy mô lớn sử dụng song song cả hai: Lettuce để xử lý hàng triệu request Cache/Session mỗi giây, và cấy thêm Redisson vào các module chuyên biệt chỉ để giải quyết bài toán Distributed Lock cho các transaction nhạy cảm.
Phần Kết: Redis – Hơn cả một bộ nhớ đệm 💎
Khép lại hành trình khám phá, chúng ta thấy rằng sức mạnh của Redis không chỉ nằm ở những con số đo lường tốc độ hàng triệu yêu cầu mỗi giây, mà còn ở sự tinh tế trong cách tổ chức dữ liệu và khả năng thích nghi linh hoạt với mọi quy mô hệ thống. Từ những cấu trúc dữ liệu "nhỏ nhưng có võ" như Ziplist đến kiến trúc phân tán mạnh mẽ của Cluster, Redis đã chứng minh mình không chỉ là một công cụ hỗ trợ (Cache) mà là một mảnh ghép chiến lược trong bức tranh kiến trúc phần mềm hiện đại. 🚀
Làm chủ Redis không chỉ là học cách gõ lệnh, mà là học cách cân bằng giữa tốc độ ánh sáng và sự an toàn tuyệt đối của dữ liệu. Khi bạn hiểu rõ từng "mắt xích" bên dưới lớp vỏ bọc đơn giản của nó, bạn không chỉ xây dựng được những ứng dụng nhanh hơn, mà còn bền bỉ và thông minh hơn. 🧠
Mình có 1 thử thách nhỏ dành cho bạn, đưa ra câu trả lời ở phía dưới comment nhé:
Chúng ta hãy cùng thử thách khả năng thiết kế hệ thống của bạn với một bài toán "oái oăm" thường gặp trong các cuộc phỏng vấn kỹ sư cấp cao nhé. Tôi sẽ đưa ra tình huống và chúng ta sẽ cùng mổ xẻ từng bước. 🧠
🧩 Thử thách: "Bóng ma" dữ liệu cũ (Stale Data)
Giả sử chúng ta đang dùng chiến lược Cache Aside:
- Khi có yêu cầu cập nhật, bạn ghi dữ liệu mới vào SQL 💾 thành công.
- Sau đó, bạn thực hiện lệnh Xóa Key đó trong Redis 🧹 để lần đọc sau sẽ lấy dữ liệu mới từ SQL.
Nghe có vẻ rất chặt chẽ, đúng không? Nhưng thực tế, trong một môi trường có hàng nghìn người dùng truy cập cùng lúc (Concurrent), tồn tại một kịch bản "đánh đố" mà ngay cả khi bạn đã xóa Redis xong, dữ liệu cũ vẫn bị nạp ngược lại vào Redis và nằm lì ở đó.
📉 Chuỗi sự kiện diễn ra như sau:
-
Tiến trình A (Người đọc): Vào đọc dữ liệu, thấy Redis trống (Cache Miss), nó sang SQL để lấy dữ liệu (lúc này vẫn là dữ liệu cũ).
-
Tiến trình B (Người viết): Cập nhật dữ liệu mới vào SQL và thực hiện xóa Redis thành công.
-
Tiến trình A: Sau khi lấy được dữ liệu cũ từ SQL (do mạng chậm hoặc DB xử lý lâu), bây giờ nó mới quay lại và thực hiện ghi dữ liệu đó vào Redis.
Kết quả: Redis hiện đang chứa dữ liệu cũ, trong khi SQL đã là dữ liệu mới. Và vì không còn lệnh xóa nào nữa, dữ liệu sai lệch này sẽ tồn tại cho đến khi Key hết hạn (TTL). 😱
Câu hỏi thử thách dành cho bạn: Theo bạn, chúng ta cần can thiệp vào bước nào hoặc thêm thao tác gì để đảm bảo "Tiến trình A" không thể nạp đè dữ liệu cũ lên Redis sau khi "Tiến trình B" đã hoàn tất việc cập nhật?
All Rights Reserved
