Các Vấn Đề Thực Tế Khi Hệ Thống Bị Quá Tải Mà Ít Ai Chia Sẻ
Source: https://www.tuanh.net/blog/devops/the-behavior-of-a-service-under-heavy-load
Một sự tăng đột biến lưu lượng đột ngột có thể gây ra nhiều vấn đề cho một dịch vụ, từ suy giảm hiệu suất và trầm trọng nhất là gây quá tải hệ thống. Bằng cách hiểu rõ các kịch bản này, bạn có thể chuẩn bị tốt hơn và triển khai các giải pháp để duy trì một dịch vụ ổn định. Bài viết này sẽ khám phá các nguyên nhân, hậu quả tiềm ẩn của lưu lượng truy cập tăng đột biến và một số gợi ý để xử lý chúng.
1. Câu chuyện của Mary ...
Mary là một nhân viên trẻ, nhiệt huyết, luôn đặt toàn bộ tâm huyết vào công việc. Cô sẵn sàng làm việc chăm chỉ từ 8 giờ sáng đến 8 giờ tối, không ngừng nỗ lực để hoàn thành nhiệm vụ và vượt quá kỳ vọng của sếp. Mặc dù đôi lúc cảm thấy mệt mỏi, nhưng hình ảnh về một tương lai giàu có và hạnh phúc luôn thúc đẩy cô tiếp tục tiến về phía trước. (Có lẽ cô chưa đọc cuốn "Cha giàu cha nghèo" nên chưa thực sự hiểu tầm quan trọng của cân bằng giữa công việc và cuộc sống.)
Tuy nhiên, sếp của Mary là một người hà khắc và mang đậm dấu ấn của một tư bản sư, ông ta nhìn thấy cô ấy như một người quá dễ bảo và háo hức muốn làm hài lòng. Ông ta thường xuyên giao thêm dự án cho cô ấy, mặc dù khối lượng công việc của cô ấy đã gấp ba lần so với một nhân viên bình thường
Cuối cùng, sau vô số ngày làm việc không ngừng nghỉ, Mary kiệt sức và ngã bệnh nặng gần một tháng. Thay vì nhận được sự hỗ trợ, công ty quyết định chấm dứt hợp đồng, khiến cô không chỉ kiệt quệ về thể chất mà còn vô cùng thất vọng và tổn thương.
2. Điều đó thì liên quan gì đến chủ đề hôm nay?
Chắc các bạn háo hức lắm phải không? Để tôi giải thích:
Câu chuyện của Mary tương đồng với những thách thức mà một dịch vụ phải đối mặt khi bị quá tải. Giống như sự nhiệt tình ban đầu của Mary dần bị thử thách bởi khối lượng công việc ngày càng tăng, một dịch vụ vốn mạnh mẽ cũng bắt đầu căng thẳng dưới áp lực của lưu lượng truy cập quá mức. Cả Mary và dịch vụ, trong khả năng tương ứng của họ, đều được yêu cầu hoạt động vượt quá giới hạn thiết kế.
Sếp của Mary, người liên tục giao thêm việc cho cô ấy, giống như một vòi nước chảy không ngừng. Cũng như một dịch vụ không thể xử lý được nhu cầu tăng lên, càng nhiều nhiệm vụ được giao thêm, Mary càng bị quá tải và cuối cùng, hiệu suất công việc của cô ấy bị ảnh hưởng.
Khi Mary phải đối mặt với khối lượng công việc quá tải, cô quyết định đa nhiệm để đáp ứng các deadline của dự án. Điều này yêu cầu Mary phải tập trung cao độ. Nếu chỉ làm một dự án, cô có thể hoàn thành trong 4 giờ. Tuy nhiên, khi phải cân bằng hai dự án cùng lúc, thời gian hoàn thành kéo dài từ 6 đến 7 giờ.
Tình huống này tương tự như một dịch vụ phải xử lý quá nhiều yêu cầu đồng thời. Khi có quá nhiều yêu cầu, các tài nguyên hệ thống như CPU và bộ nhớ phải được chia sẻ giữa chúng, dẫn đến mỗi yêu cầu nhận được ít tài nguyên hơn. Kết quả là thời gian xử lý cho mỗi yêu cầu tăng lên, và điều này có thể dẫn đến các yêu cầu mới không nhận đủ tài nguyên hoặc phải chờ đợi lâu hơn.
Sự phân bổ tài nguyên không hiệu quả này tạo ra một vòng luẩn quẩn, trong đó các yêu cầu tiếp theo ngày càng khó đáp ứng và hệ thống trở nên kém hiệu quả dần dần.
Nói cách khác, càng nhiều dự án mà Mary phải xử lý cùng một lúc, cô càng lầm vào tình cảnh không thể hoàn thành tất cả công việc trước deadline. Điều này giống như một request bị connection timeout: khi có quá nhiều dữ liệu được xử lý cùng lúc dẫn đến một số yêu cầu bị bỏ lỡ. Với quá nhiều dự án trên tay, Mary có nguy cơ không thể dành đủ sự chú ý cho từng dự án, dẫn đến chậm trễ.
Tương tự như tình trạng kiệt sức dẫn đến việc mất việc của Mary, các dịch vụ có thể gặp phải những gián đoạn nghiêm trọng, ngừng hoạt động hay bị khởi động lại khiến chúng không thể hoạt động trơn tru lúc website đang có lưu lượng truy cập tăng cao.
3. Giải thích
Giả sử bạn có một máy ảo mô phỏng cấu hình não bộ của Mary với 1 CPU (có 2 luồng ảo (vitual thread) trên mỗi CPU) và 8 GB RAM. Dưới đây là cách CPU và các worker-thread khi Mary phải xử lý nhiều tác vụ:
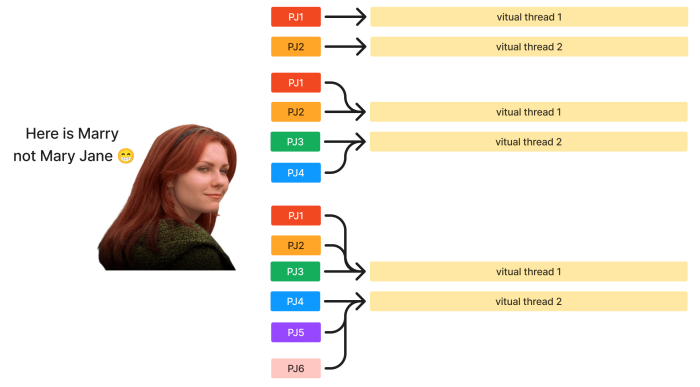
Biểu đồ này là ví dụ minh họa.
Trường hợp 1: 2 tác vụ
Cấu hình CPU: 1 CPU với 2 luồng ảo.
Số lượng tác vụ: 2.
Khi Mary nhận được 2 tác vụ và có 2 luồng ảo để xử lý, mỗi luồng ảo sẽ xử lý 1 tác vụ. Do đó, mỗi tác vụ sử dụng 1/2 CPU của Mary. Trong trường hợp này, Mary có thể xử lý hai tác vụ đồng thời mà không gặp vấn đề về hiệu suất, vì CPU có đủ luồng ảo để xử lý chúng cùng một lúc.
Trường hợp 2: 4 tác vụ
Cấu hình CPU: 1 CPU với 2 luồng ảo.
Số lượng tác vụ: 4.
Khi Mary có 4 tác vụ nhưng chỉ có 2 luồng ảo để xử lý, các tác vụ sẽ phải được xử lý tuần tự. Vì vậy, mỗi luồng ảo sẽ lần lượt thực hiện 2 tác vụ. Do đó, mỗi tác vụ chỉ sử dụng 1/4 CPU của Mary. Trong trường hợp này, do các tác vụ được thực hiện tuần tự trên các luồng ảo nên thời gian xử lý cho mỗi tác vụ sẽ dài hơn khi chỉ có 2 tác vụ.
Trường hợp 3: 6 tác vụ
Cấu hình CPU: 1 CPU với 2 luồng ảo.
Số lượng tác vụ: 6.
Khi có 6 tác vụ nhưng vẫn chỉ có 2 luồng ảo, các tác vụ sẽ tiếp tục được thực hiện tuần tự thông qua 2 luồng ảo. Mỗi tác vụ chỉ sử dụng 1/6 CPU của Mary. Chia sẻ tài nguyên CPU cho nhiều tác vụ hơn sẽ dẫn đến thời gian xử lý dài hơn và có thể giảm hiệu suất tổng thể.
Nếu bạn muốn biết thêm về Đồng bộ và Đồng thời, bạn có thể kiểm tra nó ở đây. Trong bài viết này, tôi đã nói về nó là gì, nó hoạt động như thế nào và đưa ra một số ví dụ.
4. Ví dụ
Tôi đã thử nghiệm tải trọng cho GCS. Đúng vậy, đó chính là GCS (Google Cloud Storage). Tôi đã thực hiện điều này bằng cách tạo một module và sử dụng module đó để gọi một yêu cầu nhằm tải lên một tệp vào GCS.
Nếu bạn muốn xem cách tôi tải bài kiểm tra bằng Locust, bạn có thể xem tại đây.
Đây là cấu hình dịch vụ của tôi tại thời điểm đó. Chúng chỉ được thực hiện vào những thời điểm khác nhau.
Pod:
Request:
Memory: 10G
CPU: 100m
Limit:
Memory: 10G
CPU: 15
Tổng cộng có 10 pod và kích thước tệp là 3KB.
4.1 Lần đầu

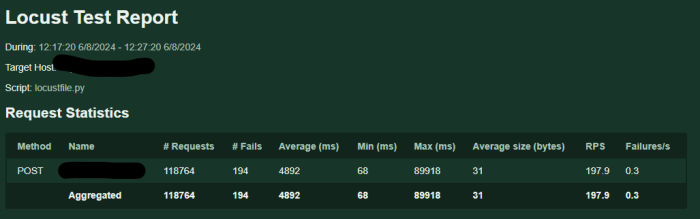
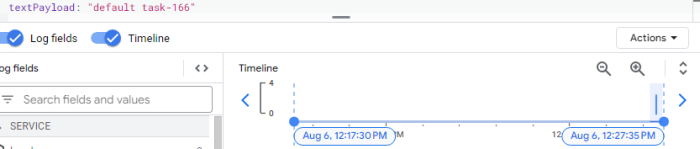
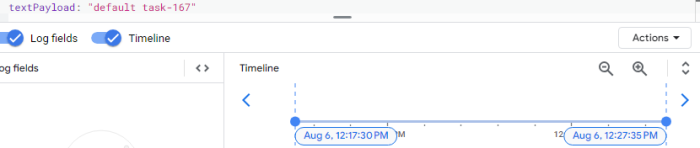
Biểu đồ này mô tả các yêu cầu thất bại trong quá trình loadtest. Tôi cũng sẽ thống kê các luồng worker được sinh ra bởi mỗi pod. Điều quan trọng cần lưu ý là có một mối quan hệ một-một giữa các yêu cầu và worker-thread: mỗi yêu cầu đến một pod kích hoạt việc tạo ra một worker-thread duy nhất.
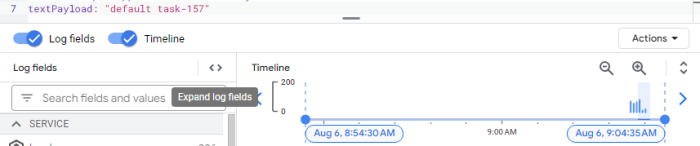
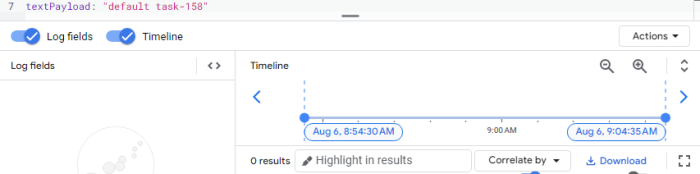
Bằng cách tìm kiếm cụm từ "default task-" trong văn bản, tôi có thể xác định được số worker-thread đang được tạo ra là bao nhiêu.
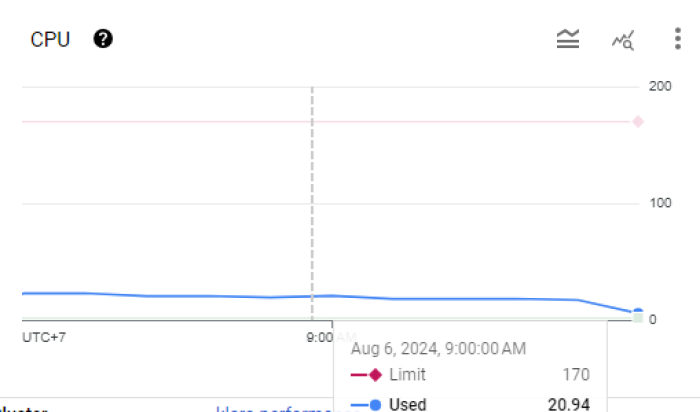
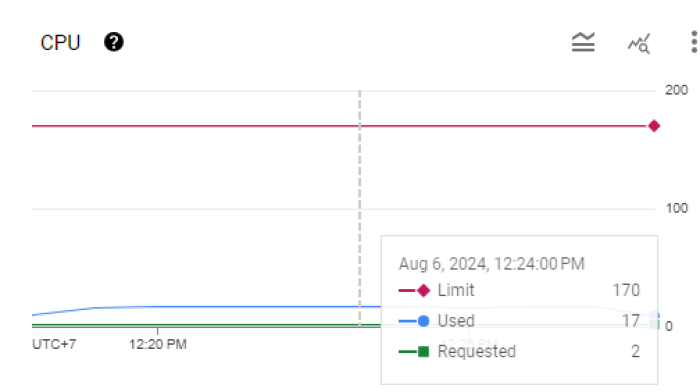
Trong giai đoạn này, sau khi tiến hành vertical scaling, các pod có xấp xỉ 21 CPU.
4.2 Lần thứ 2
Chúng ta làm tương tự lần 1
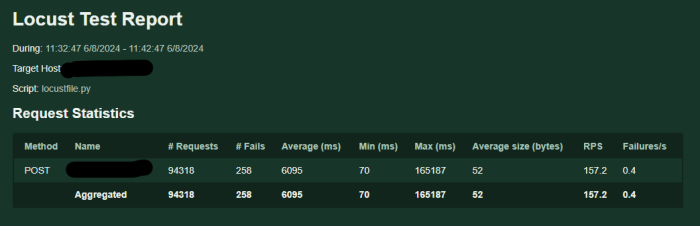
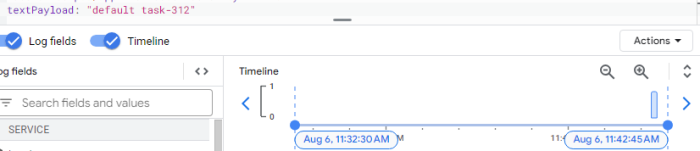
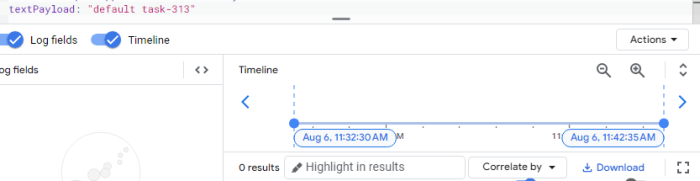
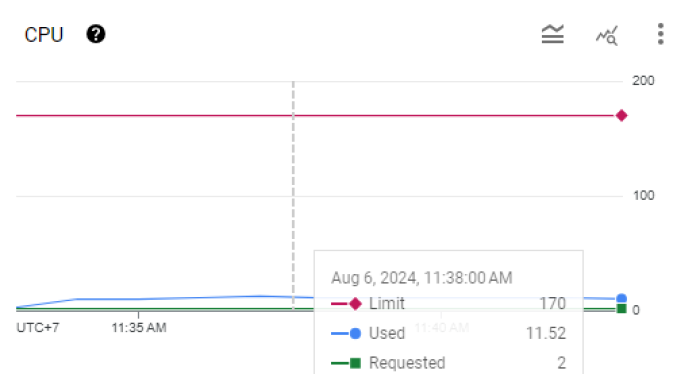
4.3 Lần thứ 3
4.4 Tổng kết

Qua 3 lần đo trên, số lượng worker-thread không nhất thiết phải cao để đạt được hiệu suất tốt. Trường hợp 1, với ít worker-thread nhất nhưng hiệu suất tốt nhất, chứng minh tầm quan trọng của việc tối ưu hóa số lượng worker-threadvà phân bổ tài nguyên CPU. Tỷ lệ CPU/worker-thread cao hơn có thể tương quan với hiệu suất tốt hơn, miễn là số lượng worker-thread không quá thấp đến mức không thể xử lý đủ yêu cầu.
Đôi khi, không thể kiểm soát số lượng worker-thread có thể là dấu chấm hết cho hệ thống của bạn.
Thoughput của 3 lần đo mà khác nhau, mặc dù chúng đều được đo trên cùng một k8s configuration, nguyên nhân gốc rễ của vấn đề này nằm ở khả năng mở rộng của CPU không nhanh chóng, dẫn đến sự tích tụ các request do tắc nghẽn xử lý. Trong trường hợp 2, mặc dù có hơn 300 worker-thread, chúng tôi chỉ có thể xử lý 94k yêu cầu và gặp 258 lỗi. Sử dụng CPU cho mỗi yêu cầu khá thấp, khoảng 0,61.
Số lượng worker-thread nhiều đến vậy là do, khi request vào pod, nó được tạo 1 worker-thread, nhưng do thời gian xử lý lâu, nên các request khác vào thì nó vẫn tiếp tục tạo ra worker-thread, trong khi những worker-thread hiện thời thì vẫn chưa được giải phóng tài nguyên.
5. Giải pháp
Tôi đề xuất các giải pháp sau:
Thứ nhất, áp dụng fault tolerance để giải quyết vấn đề nhiều yêu cầu gây tắc nghẽn. Bạn có thể tham khảo một trong những bài viết của tôi về Bulkhead
Thứ hai, áp dụng tính năng tự động mở rộng thông minh. Đôi khi, việc mở rộng pod dựa trên RAM và CPU là không đủ. Chúng ta có thể sử dụng Chỉ số Tùy chỉnh (Custom Metrics) để giải quyết vấn đề này. Để biết thêm thông tin, vui lòng tham khảo: https://cloud.google.com/monitoring/custom-metrics
Thứ ba, tối ưu hóa mã nguồn để giảm thời gian thực thi.
6. Kết luận
Tối ưu hóa hiệu suất hệ thống là một quá trình toàn diện, từ điều chỉnh các worker-thread đến quản lý tài nguyên CPU và bộ nhớ. Bằng cách triển khai các giải pháp cụ thể, bạn có thể cải thiện hiệu quả khả năng xử lý và giảm thiểu lỗi. Cảm ơn bạn đã đọc bài viết này, chúng tôi rất mong được gặp lại bạn trong các bài viết tiếp theo!
All rights reserved
