Breaking a Captcha by Machine Learning
Bài đăng này đã không được cập nhật trong 3 năm
Một ngày đẹp trời, TienNA @vigov5 gửi vào box một đường link & kêu gọi anh em "Hãy vote cho Framgia" https://chuyencuadev.com/framgia/reviews#
Đây là một trang đánh giá các công ty theo các tiêu chí "Lương thưởng & phúc lợi", "Đào tạo & học hỏi", "Quan tâm đến nhân viên", "Văn hoá công ty", "Văn phòng làm việc" với thang điểm từ 1-5.
Vào làm thử một review và thấy vài điều đáng chú ý:
- Không cần đăng nhập hay yêu cầu xác thực gì cả
- Chỉ cần nhập captcha là có thể post được
Một gợi ý rất rõ ràng cho việc break captcha và gửi review. Mình sẽ áp dụng thử bằng Machine Learning cho Framgia.
Các bước xây dựng hệ thống:
- Chuẩn bị dữ liệu ảnh captcha
- Xử lý nhiễu
- Cắt ảnh captcha
- Gắn nhãn cho từng ký tự được cắt
- Xây dựng model Softmax với Tensorflow
- Predict captcha và post review
Môi trường sử dụng: Python3.6, Tensorflow with GPU Disclaimer: Bài viết chỉ mang tính chất học hỏi, không nhằm mục đích khuyến khích nâng bi hay dìm hàng bất cứ công ty nào.
Update 2017/09/12: Mình có update thêm code sử dụng SVM, có độ chính xác cho predict tốt hơn, nếu bạn có hứng thú thì check thử trên repo của mình tại đây. nhé 
1.Chuẩn bị dữ liệu ảnh captcha
Rất đơn giản, captcha được sinh ra bởi url https://chuyencuadev.com/captcha, ta chỉ cần get về là xong
Đây là bài toán thực tế nhận diện cả ký tự lẫn số nên số lượng classes là khá lớn (26+10=36 classes), nên ta cũng phải chuẩn bị một số lượng kha khá dữ liệu. Mỗi captcha có 6 ký tự, ta sẽ get về khoảng 1000 captcha, vị chi là sẽ có khoảng 6000 ảnh để train & test. Đây là một con số không hề lớn đối với các bài toán Machine Learning, nếu không muốn nói là khá nhỏ, nhưng vì mục đích đơn giản và thời gian làm ngắn nên mình chỉ sử dụng tạm từng đó thôi. Nếu muốn nâng cao độ chính xác của model thì bạn có thể sử dụng nhiều dữ liệu hơn.
def get_data():
url = "https://chuyencuadev.com/captcha"
for i in range (1, 1000):
filename = '{0:04}.jpg'.format(i)
print(filename)
with open(filename, 'wb') as f:
response = requests.get(url)
if response.ok: f.write(response.content)
2. Xử lý nhiễu
 Như bạn có thể thấy, ảnh ban đầu khá là nhiễu khi có rất nhiều những chấm xanh đỏ tím vàng quanh các ký tự. Ta sẽ dùng Opencv và PIL để giảm nhiễu và đưa ảnh về đen trắng.
Như bạn có thể thấy, ảnh ban đầu khá là nhiễu khi có rất nhiều những chấm xanh đỏ tím vàng quanh các ký tự. Ta sẽ dùng Opencv và PIL để giảm nhiễu và đưa ảnh về đen trắng.
def reduce_noise(filename):
img = cv2.imread(filename)
dst = cv2.fastNlMeansDenoisingColored(img,None,50,50,7,21)
cv2.imwrite(filename, dst)
img = Image.open(filename).convert('L')
img = img.point(lambda x: 0 if x<128 else 255, '1')
img.save(filename)
Sau khi xử lý, ta sẽ được ảnh như thế này, đã khá ổn để ta có thể xử lý tiếp.
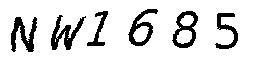
3. Cắt các ký tự
Thuật toán rất đơn giản, cũng đã được giới thiệu ở bài viết này của TienNA.
Coi ảnh giống như một ma trận các điểm, ta sẽ duyệt một vòng các cột của ma trận từ trái sang phải. Tại mỗi cột, nếu cột đó có pixel màu đen thì có nghĩa là cột đó chứa một phần ký tự. Ta ghi nhớ index cột khi bắt đầu chạm vào ký tự và cột khi bắt đầu ra khỏi ký tự bằng các biến found và in_letter, sau đó cắt các ký tự ra theo các giá trị đó. Các ảnh cắt ra phải cùng một kích cỡ, nên đồng thời với cắt ta sẽ resize ảnh về kích cỡ phù hợp, ở đây mình chọn là 30x60.
def crop(filename, outpath):
global part
img = Image.open(filename)
p = img.convert('P')
w, h = p.size
letters = []
start, end = -1, -1
found = False
for i in range(w):
in_letter = False
for j in range(h):
if p.getpixel((i,j)) == 0:
in_letter = True
break
if not found and in_letter:
found = True
start = i
if found and not in_letter and i-start > 25:
found = False
end = i
letters.append([start, end])
origin = filename.split('/')[-1].split('.')[0]
for [l,r] in letters:
if r-l < 40:
bbox = (l, 0, r, h)
crop = img.crop(bbox)
crop = crop.resize((30,60))
crop.save(outpath + '{0:04}_{1}.jpg'.format(part, origin))
part += 1
Nhìn vào ảnh cắt ra, ta thấy rằng vẫn còn phần thừa trắng 2 bên phía trên dưới. Ta tiếp tục cắt và resize về một kích cỡ nhỏ hơn nữa, ở đây là 30x36.
def adjust(path, filename):
img = Image.open(join(path, filename))
p = img.convert('P')
w, h = p.size
start, end = -1, -1
found = False
for j in range(h):
in_letter = False
for i in range(w):
if p.getpixel((i,j)) == 0:
in_letter = True
break
if not found and in_letter:
found = True
start = j
if found and not in_letter and j-start > 35:
found = False
end = j
bbox = (0, start, w, end)
crop = img.crop(bbox)
crop = crop.resize((30,36))
crop.save(join(path, filename))
Ta sẽ được các ký tự giống như thế này:

4. Gắn nhãn cho dữ liệu
Đối với các bài toán Machine Learning, thì gắn nhãn cho dữ liệu thực sự luôn luôn là công việc hại não và mất nhiều công sức nhất. Bài toán này cũng không phải là ngoại lệ.
Có nhiều cách để gắn nhãn (label) cho một tập dữ liệu, tùy vào đặc thù bài toán mà ta sẽ lựa chọn:
- Đánh thủ công bằng tay
- Sử dụng các API có sẵn
- Tự viết script
- Sử dụng các model Machine Learning đã được train sẵn
Trong bài toán này thì mình không biết model Machine Learning nào đã được train sẵn, cũng như API OCR nào, nên mình sẽ tự viết một hàm để detect với một độ chính xác tàm tạm, sau đó kiểm tra lại bằng tay. Phải nói là khổ!
Ý tưởng thuật toán là mình sẽ xây dựng một list ảnh các character từ 0-9A-Z, sau đó với mỗi ảnh ký tự, ta sẽ so sánh với tất cả các ảnh trong đó, lấy cái gần nhất và gắn nhãn cho nó, sau đó đưa nó vào list ảnh để dùng cho nhận diện ảnh tiếp theo. Sau vài lần như vậy, số lượng ảnh sai còn lại mình sẽ xử lý bằng tay, bằng cách xóa hoặc đánh nhãn mới.
def detect_char(path, filename):
class Fit:
letter = None
difference = 0
best = Fit()
_img = Image.open(join(path, filename))
for img_name in list_chars:
current = Fit()
img = Image.open(join('data/chars', img_name))
current.letter = img_name.split('-')[0]
difference = ImageChops.difference(_img, img)
for x in range(difference.size[0]):
for y in range(difference.size[1]):
current.difference += difference.getpixel((x, y))/255.
if not best.letter or best.difference > current.difference:
best = current
if best.letter == filename.split('-')[0]: return
print(filename, best.letter)
rename(path, filename, best.letter)
5. Xây dựng model Softmax với Tensorflow
Có khá nhiều mô hình có thể áp dụng được với các bài toán nhận diện ký tự như là k-means Clustering, Softmax, các mạng Neural Network. Ở bài này mình sẽ sử dụng Softmax.
Về library thì mình sử dụng Tensorflow, đây là một thư viện mạnh mẽ, được Google tạo ra và support, cung cấp cả API high-level và low-level nên có thể thích hợp với tất cả các app từ nhỏ tới các hệ thống business lớn, đồng thời chạy cả trên CPU và GPU. Có thể nói Tensorflow là thư viện mạnh nhất để thực hiện Machine Learning.
Do giới hạn của bài viết, mình sẽ không đi sâu vào các kiến thức toán học của Softmax mà sẽ đi vào code luôn. Nếu các bạn muốn tìm hiểu thì có thể đọc thêm tại Softmax Regression
Đối với đầu vào, mỗi bức ảnh lúc nãy được ta cắt ra có kích cỡ 30x36 (=1080), ta sẽ đưa nó vào dưới dạng vector một chiều, có kích cỡ là 1x1080.
Đối với đầu ra, có 36 classes, ta sẽ dùng một vector 1x36 để đại diện. Với mỗi vector thì tất cả các giá trị tại index ứng với ký tự của ảnh là 1, còn lại là 0. Vector dạng này gọi là "one-hot" vector.
Toàn bộ dữ liệu sẽ được chia ra làm 2 phần, phần train với 80% dữ liệu, phần test với 20% dữ liệu.
# tf Graph Input
x = tf.placeholder(tf.float32, [None, 1080])
y = tf.placeholder(tf.float32, [None, 36])
W = tf.Variable(tf.zeros([1080, 36]))
b = tf.Variable(tf.zeros([36]))
pred = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
init = tf.global_variables_initializer()
Train & Test
Chạy 1000 bước với dữ liệu:
for i in range(1000):
_, _cost = sess.run([optimizer, cost], feed_dict={x: images_train, y: labels_train})
print("cost = {:.9f}".format(_cost))
print("Optimization Finished!")
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print("Accuracy:", accuracy.eval({x: images_test, y: labels_test}))
Kết quả:
Loading images...
(4047, 1080) (4047, 36) (1012, 1080) (1012, 36)
Start training...
cost = 0.225842983
Optimization Finished!
Accuracy: 0.981225
Model saved in file: tmp/softmax.ckpt
Predict
Sau khi đã train xong, ta xây dựng hàm predict để nhận diện ký tự và xâu captcha:
def predict_char(img_path):
img = np.array(Image.open(img_path).convert('L')).reshape(1080,)
for i in range(1080): img[i] = img[i]/255.
with tf.Session() as sess:
sess.run(init)
saver.restore(sess, model_path)
predict = tf.argmax(pred, 1)
return chars[predict.eval({x:[img]})[0]]
def predict(filename):
res = ''
reduce_noise(filename)
out_path = 'tmp/null/'
files = glob.glob(out_path+'*')
for f in files: os.remove(f)
crop(filename, out_path)
adjust_folder(out_path)
files = sorted([f for f in listdir(out_path) if isfile(join(out_path, f)) and 'jpg' in f])
for f in files:
res += predict_char(out_path+f)
print(res)
return res
6. Post Review
Với 5 tiêu chí để post, mình sẽ random các kết quả từ 3-5 để đảm bảo vote cho Framgia sẽ không thấp =))
salary_benefit_rate = random.randrange(3,6,1)
training_learning_rate = random.randrange(3,6,1)
management_care_rate = random.randrange(3,6,1)
culture_fun_rate = random.randrange(3,6,1)
office_workspace_rate = random.randrange(3,6,1)
payload = {
"salary_benefit_rate":f"{salary_benefit_rate}",
"training_learning_rate":f"{training_learning_rate}",
"management_care_rate":f"{management_care_rate}",
"culture_fun_rate":f"{culture_fun_rate}",
"office_workspace_rate":f"{office_workspace_rate}",
}
payload["captcha"] = predict('captcha.jpg')
# raw_input().strip()
# print(payload)
r = s.post(f"https://chuyencuadev.com/{company_name}/review", headers=headers, data=payload)
Yeah, ta đã có review về Framgia trên trang https://chuyencuadev.com/framgia/reviews
Tại thời điểm mình viết bài viết này thì số lượng review của Framgia đang là nhiều nhất =))
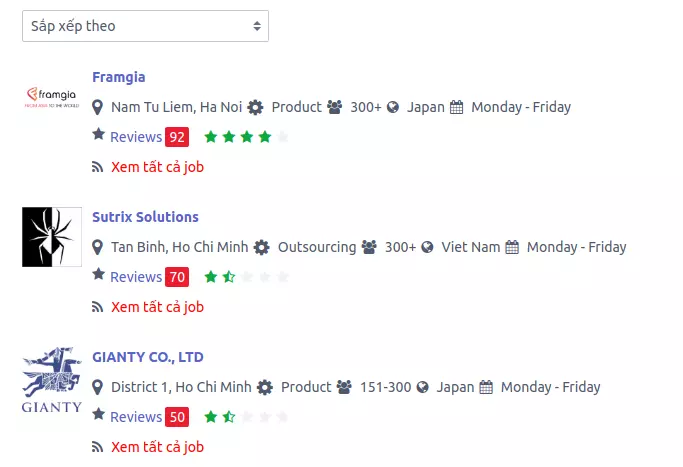 Vậy là chúng ta đã hoàn thành một study nhỏ về Machine Learning. Hi vọng là các bạn có những trải nghiệm thú vị, và hi vọng chuyencuadev.com sớm update captcha mới khó hơn.
Vậy là chúng ta đã hoàn thành một study nhỏ về Machine Learning. Hi vọng là các bạn có những trải nghiệm thú vị, và hi vọng chuyencuadev.com sớm update captcha mới khó hơn.
Có một điều mình chưa hài lòng lắm, là kết quả training khá tốt, cho chính xác tới tận 98% mà khi predict thì kết quả lại khá là tệ, đây có thể coi là một thử thách nhỏ cho bạn đọc để nâng độ chính xác của mô hình. Nếu bạn có cách làm tốt hơn, hãy chỉ cho mình nhé.
Toàn bộ source code của chương trình được public tại đây.
Cảm ơn các bạn đã quan tâm theo dõi !
All rights reserved
