Apache Kafka: "Hệ thần kinh trung ương" của kiến trúc hướng sự kiện (Event-Driven)
Chào mọi người lại là mình đây,
Hôm nay hãy cùng mình phân tích tấm ảnh này nhé
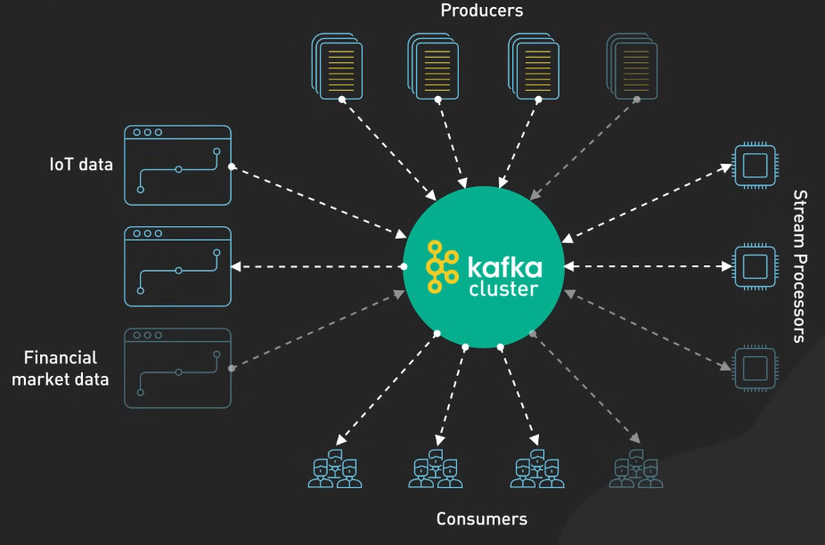
Tấm ảnh này chính là mô tả sống động về "Hệ thần kinh trung ương" của một hệ thống xử lý dữ liệu hiện đại. Nếu các service trong mô hình Microservices mà chúng ta vừa phân tích là các cơ quan nội tạng, thì Apache Kafka chính là dòng máu mang thông tin lưu khắp cơ thể đó.
Hãy cùng mình "giải mã" sơ đồ này để thấy tại sao Kafka lại là "quái vật" không thể thiếu trong các bài toán Big Data và Real-time Processing nhé!
1. Trái tim của hệ thống: Kafka Cluster
Nằm ở chính giữa sơ đồ là Kafka Cluster. Đừng nhầm nó với các Message Queue truyền thống như RabbitMQ. Kafka không chỉ gửi tin nhắn rồi xóa đi: nó là một Distributed Streaming Platform (Nền tảng truyền phát dữ liệu phân tán).
- Lưu trữ bền vững: Kafka lưu dữ liệu dưới dạng các bản ghi (log) trên đĩa cứng. Điều này có nghĩa là nếu "người nhận" bị sập, dữ liệu vẫn nằm đó chờ họ sống lại để đọc tiếp
- Khả năng mở rộng: Nó được thiết kế để chạy trên cụm máy chủ (cluster). Khi dữ liệu tăng vọt, bạn chỉ cầ ném thêm server vào, Kafka sẽ tự động chia tải.
2. Đầu vào: Producers & External Data
Ở phía trên và bên trái sơ đồ, chúng ta thấy Producers và các nguồn dữ liệu như IoT data, Financial market data.
- Producers (Người sản xuất): Đây là các ứng dụng đẩy dữ liệu vào Kafka. Đặc điểm quan trọng nhất ở đây là tính Bất đồng bộ (Asynchronous).
- IoT & Finance: Đây là hai nguồn dữ liệu điển hình của Kafka. Cảm biến IoT gửi hàng triệu tín hiệu mỗi giây, hay sàn chứng khoán biến động liên tục. Kafka "nuốt" hết đống dữ liệu khổng lồ này mà không hề hấn gì nhờ cơ chế ghi tuần tự (sequential write) cực nhanh.
3. Đầu ra: Consumers
Ở phía dưới là các Consumers (Người tiêu thụ).
- Cơ chế Pull: Trong Kafka, Consumer chủ động "kéo" dữ liệu khi họ sẵn sàng, thay vì bị Broker "nhồi nhét" (push). Điều này giúp các service yếu hơn không bị sập khi gặp đỉnh tải (spike).
- Nhiều người cùng đọc: Một sự kiện (event) trong Kafka có thể được đọc bởi nhiều Consumer khác nhau cho các mục đích khác nhau (ví dụ: một đơn hàng vừa được tạo, Service Kho lấy để đóng gói, Service Kế toán lấy để xuất hóa đơn).
4. Bộ não xử lý: Stream Processors
Phía bên phải sơ đồ mô tả các Stream Processors. Đây là nơi dữ liệu được "chế biến" ngay khi đang chảy qua hệ thống.
- Thay vì đợi dữ liệu đổ vào Database rồi mới chạy query để thống kê (Batch Processing), Stream Processing cho phép bạn tính toán Real-time.
- Ví dụ: Phát hiện gian lận thẻ tín dụng ngay tại thời điểm quẹt thẻ, hoặc tính toán lại giá Grab dựa trên nhu cầu của khách hàng ngay trong tích tắc.
5. Tại sao mô hình này lại "đỉnh"?
Nhìn vào các mũi tên tỏa ra từ tâm, chúng ta thấy sự Decoupling (Ngắt kết nối) tuyệt vời:
- Người gửi không cần biết người nhận là ai: Bạn cứ đẩy log vào Kafka, ai cần thì đăng ký (Subscribe) mà lấy.
- Khả năng chịu lỗi cao: Dữ liệu được nhân bản (Replication) ra nhiều node. Một node chết, hệ thống vẫn chạy phăm phăm.
- Back pressure: Kafka đóng vai trò như một "bình chứa trung gian", giúp ổn định dòng chảy dữ liệu, tránh việc các service phía sau bị quá tải.
Lời kết
Nếu bạn đang xây dựng các hệ thống yêu cầu độ trễ thấp và khối lượng dữ liệu lớn, Kafka chính là "vũ khí hạng nặng" cần phải master. Nó biến dữ liệu từ trạng thái "tĩnh" trong database thành trạng thái "động" xuyên suốt hệ thống.
Trong dự án của mình, bạn đã từng gặp case nào mà hệ thống bị nghẽn do xử lý đồng bộ (Synchronous) quá nhiều chưa? Bạn có nghĩ việc đưa Kafka vào sẽ giải quyết được "nỗi đau" đó không?
All rights reserved
